1.11 Python 中的可迭代对象、迭代器与生成器¶
前言¶
Hi,大家好,我是可乐, 迭代器 与 生成器 是 Python
学习中不可避免的两个有趣的知识点,实际开发中也比较常用。
我们在处理大量数据时,有时会导致计算机内存不足,我们需要将数据分块处理,只处理所需的数据,这将大大减少计算机内存的消耗,这便是迭代器与生成器最直观的作用。

今天,我们一起来探索 迭代器 与 生成器
的相关知识,并附上相关案例代码,便于吸收、理解。
聊到这,我们不得不提起 可迭代对象
这个概念,首先我们用一张图片来展示它们三者之间的关系。
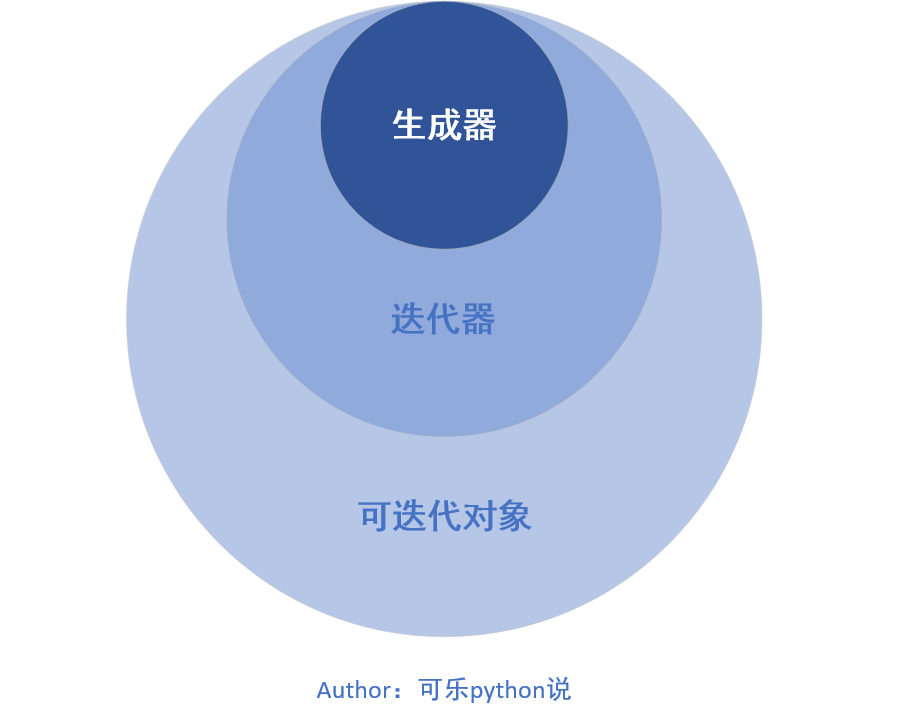
可迭代对象¶
可迭代对象(Iteratable Object)
是能够一次返回其中一个成员的对象,通常使用我们之前介绍过的 for 循环
来完成此操作,如字符串、列表、元组、集合、字典等等之类的对象都属于可迭代对象。
简单来理解,任何你可以循环遍历的对象都是可迭代对象。
1、使用 isinstance()函数 判断对象是否是可迭代对象
# 导入 collections 模块的 Iterable 对比对象
>>> from collections import Iterable
# 字符串是可迭代对象
>>> isinstance("kele", Iterable)
True
# 列表是可迭代对象
>>> isinstance(["kele"], Iterable)
True
# 字典是可迭代对象
>>> isinstance({"name":"kele"}, Iterable)
True
# 集合是可迭代对象
>>> isinstance({1,2}, Iterable)
True
# 数字不是可迭代对象
>>> isinstance(18, Iterable)
False
2、使用 dir()函数 查看对象内所有的属性与方法
# 字符串的所有属性与方法
>>> dir("kele")
[..., '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', ...]
# 列表的所有属性与方法
>>> dir(["kele"])
[..., '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__',...]
# 字典的所有属性与方法
>>> dir({"name":"kele"})
[..., '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', ...]
# 数字的所有属性与方法
# 并没有找到 __iter__
>>> dir(18)
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
3、对比可迭代对象与不可迭代对象的所有属性与方法,我们发现:可迭代对象都构建了 ``__iter__`` 方法,而不可迭代对象没有构建,因此我们也可通过此特点来判断某一对象是不是可迭代对象。
4、我们来验证一下这个结论
# 没有定义 __iter__ 方法则是不可迭代对象
>>> from collections import Iterable
>>> class IsIterable:
pass
>>> isinstance(IsIterable(), Iterable)
False
# 定义 __iter__ 方法则是可迭代对象
>>> class IsIterable:
def __iter__(self):
pass
>>> isinstance(IsIterable(), Iterable)
True
5、看到这里,抛出一个思考, __iter__
方法有什么作用,执行它我们能得到什么?
# 调用后,得到了一个与调用对象对应的对象 - iterator
>>> "kele".__iter__()
<str_iterator object at 0x0462CB30>
>>> ["kele"].__iter__()
<list_iterator object at 0x0462CA50>
这里得到的新对象,正是我们接下来要介绍的内容 - 迭代器。
迭代器¶
迭代器(Iterator) 是同时实现__iter__() 与 __next__()
方法的对象。
它可通过 __next__() 方法或者一般的 for
循环进行遍历,能够记录每次遍历的位置,迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束,迭代器只能往前不能后退,终止迭代则会抛出
StopIteration 异常。
1、迭代器是可迭代对象
>>> from collections import Iterable
# 以我们前面得到的迭代器为例
>>> isinstance("kele".__iter__(), Iterable)
True
2、使用 dir()函数 查看迭代器所有的属性与方法
>>> dir("kele".__iter__(), Iterable)
# 我们可以看到迭代器同时实现
# __iter__ 与 __next__ 方法
[..., '__iter__', '__le__', '__length_hint__', '__lt__', '__ne__', '__new__', '__next__', ...]
3、使用 __next__() 方法获取迭代器中的元素
>>> str_iterator = "kele".__iter__()
>>> str_iterator.__next__()
'k'
>>> str_iterator.__next__()
'e'
>>> str_iterator.__next__()
'l'
>>> str_iterator.__next__()
'e'
>>> str_iterator.__next__()
# 终止迭代则会抛出 StopIteration 异常
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
4、使用 next() 与 iter() 方法来实现相同的效果
# 使用 iter() 方法获取一个迭代器
>>> str_iterator = iter("kele")
# 使用 next() 方法获取迭代器中的元素
>>> next(str_iterator)
'k'
>>> next(str_iterator)
'e'
>>> next(str_iterator)
'l'
>>> next(str_iterator)
'e'
>>> next(str_iterator)
# 终止迭代则会抛出 StopIteration 异常
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
5、自己动手实现一个迭代器类,返回偶数
>>> class MyIterator:
"""
迭代器类
Author:可乐python说
"""
# 类构造函数,调用时最先执行
# 用于分配执行最初所需的任何值
def __init__(self):
self.num = 0
# iter()和next()方法使这个类变成迭代器
def __iter__(self):
# 类本身就是迭代器,故直接返回本身
return self
def __next__(self):
# 返回当前值
return_num = self.num
# 并改变下一次调用的状态
self.num += 2
return return_num
>>> my_iterator = MyIterator()
>>> next(my_iterator)
0
>>> next(my_iterator)
2
>>> next(my_iterator)
4
# 思考:for 循环为什么能够自动结束遍历?
6、前文实现的迭代器类,并没有写结束的条件,这里优化一下
>>> class MyIterator:
"""
迭代器类
Author:可乐python说
"""
def __init__(self):
self.num = 0
def __iter__(self):
return self
def __next__(self):
return_num = self.num
# 只要值大于等于6,就停止迭代
if return_num >= 6:
raise StopIteration
self.num += 2
return return_num
>>> my_iterator = MyIterator()
>>> next(my_iterator)
0
>>> next(my_iterator)
2
>>> next(my_iterator)
4
>>> next(my_iterator)
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
7、我们还可对异常进行处理,获取到 StopIteration 异常便退出循环
>>> class MyIterator:
# 以上略...
def __next__(self):
return_num = self.num
# 只要值大于等于6,就停止迭代
if return_num >= 6:
raise StopIteration
self.num += 2
return return_num
>>> my_iterator = MyIterator()
>>> while True:
try:
my_num = next(my_iterator)
except StopIteration:
break
print(my_num)
0
2
4
我们对迭代器捕获异常后,其实就是实现了与 for 循环类似的效果,这也正是 for 循环底层实现的方式,当迭代一个可迭代对象时,for 循环通过 iter() 方法获取要迭代的项,并使用 next() 方法返回后续的项。
迭代器可通过两种方式获取:一种是调用迭代器类中的方法直接返回迭代器,另一种是可迭代对象通过执行
__ iter()__
方法获取,迭代器在一定程度上节省了内存,需要时才去获取对应的数据。
在某些情况下,我们不想遵循迭代器协议,即不想实现__iter__() 与 __next__()
方法
,但我们又想实现与迭代器相同的功能,这时,就需要使用到一种特殊的迭代器,这正是我们接下来要介绍的内容
- 生成器。
生成器¶
Python 中,提供了两种 生成器(Generator)
,一种是生成器函数,另一种是生成器表达式。
生成器函数,定义与常规函数相同,区别在于,它使用 yield 语句
而不是 return 语句 返回结果, yield
语句一次返回一个结果,在每个结果中间,会暂停并保存当前所有的运行信息,以便下一次执行
next() 方法时从当前位置继续运行。
生成器表达式,与列表推导式类似,区别在于,它使用小括号 - ()
包裹,而不是中括号,生成器返回按需产生结果的一个对象,而不是一次构建完整的列表。
1、动手实现一个生成器函数
>>> def my_generator():
my_num = 0
while my_num < 5:
yield my_num
my_num += 1
>>> generator_ = my_generator()
# 得到一个生成器对象
>>> type(generator_)
<class 'generator'>
2、生成器也是迭代器
# 以上略...
>>> generator_ = my_generator()
# 可发现 __iter__ 与 __next__ 方法
>>> dir(generator)
[..., '__iter__', '__le__', '__lt__', '__name__', '__ne__', '__new__', '__next__', ..., 'send', 'throw']
3、传统方式获取生成器的元素
# 以上略...
>>> generator_ = my_generator()
>>> next(generator_)
0
>>> next(generator_)
1
>>> next(generator_)
2
>>> next(generator_)
3
>>> next(generator_)
4
>>> next(generator_)
# 终止迭代则会抛出 StopIteration 异常
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
4、使用 for 循环获取生成器元素
# 以上略...
>>> generator_ = my_generator()
>>> for num_ in generator_:
print(num_)
0
1
2
3
4
5、生成器表达式与列表生成式
聊到这,大家不妨思考一下,我们为什么要使用生成器?
我们以一个简单例子来对比一下,两者实现相同功能的内存消耗。
使用列表生成式获取一个包括 100 万个元素的列表,借用 sys 模块计算内存
>>> import sys
>>> my_list = [i for i in range(1000000)]
# 调用 sys.getsizeof() 获取内存消耗
>>> print("列表消耗的内存:{}".format(sys.getsizeof(my_list)))
列表消耗的内存:4348736
下面,我们看看生成器表达式
>>> import sys
>>> my_generator = [i for i in range(1000000)]
>>> print("生成器消耗的内存:{}".format(sys.getsizeof(my_generator)))
列表消耗的内存:56
很明显,对于相同数量的项,列表生成式和生成器在内存消耗上存在巨大差异,这就是我们为什么要使用生成器的原因。
应用 - 使用 yield 实现斐波那契数列¶
斐波那契数列(Fibonacci sequence),又称黄金分割数列、因数学家列昂纳多·斐波那契(Leonardoda
Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”。
指的是这样一个数列:1、1、2、3、5、8、13、21、34、……在数学上,斐波纳契数列以如下被以递推的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)
今天,我们使用 Python 中的 yield 来实现
>>> def fibonacci(n):
"""斐波那契数列实现"""
a, b = 0, 1
while n > 0:
a, b = b, a + b
n -= 1
yield a
# 获取斐波那契数列前 10 个成员
>>> fibonacci_ = fibonacci(10)
for i in fibonacci_:
print(i)
1
1
2
3
5
8
13
21
34
55
扩展 - itertools 库简介¶
itertools
中的大多数函数是返回各种迭代器对象,如果自己去实现同样的功能,代码量会非常大,而在运行效率上反而更低,因此,我们很有必要了解一下这个标准库。

获取指定数目内正整数的累加和
>>> import itertools
# 获取 10 以内的正整数累加和
>>> cumulative_sum = itertools.accumulate(range(10))
# 转换为列表
>>> print(list(cumulative_sum))
[0, 1, 3, 6, 10, 15, 21, 28, 36, 45]
获取指定数目元素的所有排列(顺序有关)
>>> import itertools
# 获取元素 1、2、3 的所有排列结果
>>> array_result = itertools.permutations((1, 2, 3))
# 转换为列表
>>> print(list(array_result))
[(1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2, 1)]
总结¶
迭代器属于可迭代对象,生成器是特殊的迭代器。
可迭代对象都构建了
__iter__方法,迭代器还需构建__next__()方法。生成器是一种特殊的迭代器,内部支持了生成器协议,不需要明确定义
__iter__方法和__next__()方法。列表生成式的效率远高于 for 循环语句嵌套,生成器的效率远高于列表生成式。
获取可迭代对象的元素时,强烈推荐 for 循环,因为它具备自动处理异常的能力。
Python 中,包含 yield 关键词的普通函数就是生成器。
文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,也可分享迭代器、与生成器相关的技巧、以及有趣的案例。
原创文章已全部更新至 Github :https://github.com/kelepython/kelepython
本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c01/c01_11.html
