可乐python说¶
前言¶
关于博客¶
这个网站是我的首个博客,博客名字叫《可乐python说》,此博客于2020年4月20日发布完成,使用的是 Sphinx 来生成文档,使用 Github 托管文档,并使用 Read the Doc 发布文档。
作者的话¶
Python 语言诞生于 1991 年,经过近30年的发展,Python 不仅没有被其他的编程语言 PK 下去,反而在人工智能、 Web、爬虫、数据分析、自动化运维等领域得到广泛应用。
此博客记录的是我个人首发于个人公众号「可乐python说」的文章,主要是记录我学习、工作当中的一些 Python 相关的知识,当然也会分享我生活当中的一些故事。
由于我个人从事开发工作的时间也不是很长,所以请你在阅读本站内容时,带着质疑的态度,这既能帮助自己思考,也能发现我文章当中的不足,文章中如果有什么错误、或者遗漏的地方请大家见谅,也欢迎大家随时加我微信帮我指正,十分感谢!

第一章:基础知识¶
这一章介绍 Python 最基础的入门知识点,如:数据类型、基本操作等
本章节,会持续更新,敬请关注...
1.1 一文搞定 Python 字符串操作(上)¶
前言¶
Python3 中有六个标准的数据类型,它们分别是数字(Number)、字符串(String)、列表(List)、元组(Tuple)、集合(Set)、字典(Dictionary)。
数据类型分类可变数据类型、和不可变数据类型,其中可变类型包括列表、字典、集合,不可变类型包括数字、字符串、元组。
本文主要介绍 Python 中字符串的内建函数,并配上相关代码,便于理解、吸收。

字符串简介¶
Python中的字符串使用单引号 '' 或双引号 "" 括起来,同时使用反斜杠
\
转义特殊字符,实际工作当中,接触、处理最多的数据类型,莫过于字符串了。
下面使用两种方式定义字符串,两种方式均可
single_str = 'a我是单引号括起来的字符串'
type(single_str) # type 查看数据类型
double_str = "a我是双引号括起来的字符串"
type(double_str) # type 查看数据类型
字符串操作¶
我将字符串操作分为五大类,分别是通用类、英文单词类、判断类、编码类、以及其他类,今天先介绍一下通用类的相关操作。
通用类¶
replace(old, new [, max]),把 将字符串中的 old 替换成 new, max 为可选参数,若指定 max ,则替换 max 次。
double_str = "my name is kele kele"
double_str.replace("kele", "xuebi")
'my name is xuebi xuebi'
double_str.replace("kele", "xuebi", 1)
'my name is xuebi xuebi'
split(str="", num=string.count(str)),以 str 为分隔符截取字符串,默认为所有的空字符,包括空格、换行
\n、制表符\t等。若指定 num ,则截取出 num+1 个子字符串,返回包含所有字符串的列表。
# 使用语法:str.split(str="", num=string.count(str))
# 用法一:不指定 num ,截取所有
double_str = "mynameiskelekelea"
double_str.split("e")
['mynam', 'isk', 'l', 'k', 'l', 'a']
# 用法二:指定 num ,截取 num 次
double_str.split("e", 1)
['mynam', 'iskelekelea']
splitlines([keepends]),按照行('', '', ')分隔,返回一个包含各行作为元素的列表,参数 keepends 默认为 False,不包含换行符,如果为 True,则保留换行符。
# 使用语法:str.splitlines([keepends])
# 用法一:不指定 keepends,默认为 False
double_str = "my name\nis ke\rle\r\n"
double_str.splitlines()
['my name', 'is ke', 'le']
# 用法一:指定 keepends 为 True, 保留切割符
double_str.splitlines(True)
['my name\n', 'is ke\r', 'le\r\n']
len(string),返回字符串的长度。
# 使用语法:len(string)
double_str = "my name is kele"
len(double_str)
15
find(str, beg=0, end=len(string)),检测 str 是否包含在字符串中,若指定 beg 和 end ,则在指定范围内检测,若包含则返回第一次出现的索引值,否则返回 -1。
# 使用语法:str.find(str, beg=0, end=len(string))
double_str = "my name is kele"
double_str.find("h")
-1
double_str.find("e")
6
# 指定范围
double_str.find("i",0,5)
-1
rfind(str, beg=0,end=len(string)),与 find() 函数类似,但它是从右边开始查找,返回字符串最后一次出现的索引值。
# 使用语法:str.rfind(str, beg=0, end=len(string))
double_str = "my name is kele"
double_str.rfind("h")
-1
double_str.rfind("e")
14
# 指定范围
double_str.rfind("i",0,5)
-1
index(str, beg=0, end=len(string)),与 find() 函数类似,但如果 str 不在字符串中会报如下错误。
# 使用语法:str.index(str, beg=0, end=len(string))
double_str = "my name is kele"
double_str.index("h") # 元素不在字符串中回报错
double_str.index("e")
6
# 指定范围
double_str.index("a", 0, 5)
4
rindex( str, beg=0, end=len(string)),类似于 index(),不过是从右边开始,返回字符串最后一次出现的索引值。
# 使用语法:str.rindex(str, beg=0, end=len(string))
double_str = "my name is kele"
double_str.rindex("h") # 元素不在字符串中回报错
double_str.rindex("e")
14
# 指定范围
double_str.rindex("a", 0, 5)
4
count(str, beg= 0,end=len(string)),返回 str 在 string 中出现的次数,若指定 beg 或者 end 参数,则返回在指定范围内 str 出现的次数。
# 使用语法:str.count(str, beg=0, end=len(string))
double_str = "my name is kele"
double_str.count("h")
0
double_str.count("e")
3
# 指定范围
double_str.count("e", 0, 7)
1
lstrip([chars]),只处理字符串句首的空格或指定字符,其他位置忽略。
# 使用语法:str.lstrip([chars\)
# 处理句首空格
double_str = " 句首 有两个空格"
double_str.lstrip()
'句首 有两个空格'
# 处理句首指定字符
double_str = "句首句首有一个空格"
double_str.lstrip("句首")
'有一个空格'
rstrip([chars]),处理字符串末尾的空格或指定字符,其他位置忽略 。
# 使用语法:str.rstrip([chars])
# 处理句尾空格
double_str = "句子末尾 有两个空格 "
double_str.rstrip()
'句子末尾 有两个空格'
# 处理句尾其他字符
double_str = "句尾有一个空格空格"
double_str.rstrip("空格")
'句尾有一个'
strip([chars]), 处理字符串两端的空格或指定字符,可视为 lstrip() 和 rstrip() 的效果叠加。
# 使用语法:str.strip([chars])
# 处理两端的空格
double_str = " 句首 句尾均有空格 "
double_str.strip()
'句首 句尾均有空格'
# 处理两端的指定字符
double_str = "你好有一个 空格你好"
double_str.strip("你好")
'有一个 空格'
center(width, fillchar),fillchar 为填充的字符,默认使用空格填充,返回指定宽度 width、原字符串居中、使用 fillchar 填充后的字符串。
# 使用语法:str.center(width, fillchar)
# 用法一:不指定填充字符,默认使用空字符填充
double_str = "我想通过两侧填充来让自己变强"
double_str.center(20)
' 我想通过两侧填充来让自己变强 '
# 用法二:指定填充字符 【*】
double_str.center(20, "*")
'***我想通过两侧填充来让自己变强***'
ljust(width, fillchar)),fillchar 为填充的字符,默认使用空格填充,返回指定宽度 width、原字符串左对齐、使用 fillchar 填充后的字符串。
# 使用语法:str.ljust(width, fillchar)
# 用法一:不指定填充字符,默认使用空字符
double_str = "我想通过右侧填充让自己变强"
double_str.ljust(20)
'我想通过右侧填充让自己变强 '
# 用法二:指定填充字符 【*】
double_str.ljust(20, "*")
'我想通过右侧填充让自己变强*******'
rjust(width, fillchar),fillchar 为填充的字符,默认使用空格填充,返回指定宽度 width、原字符串靠右对齐、使用 fillchar 填充后的字符串。
# 使用语法:str.rjust(width, fillchar)
# 用法一:不指定填充字符,默认使用空字符
double_str = "我想通过左侧填充让自己变强"
double_str.rjust(20)
' 我想通过左侧填充让自己变强'
# 用法二:指定填充字符 【*】
double_str.rjust(20,"*")
'*******我想通过左侧填充让自己变强'
zfill (width),返回长度为 width 的字符串,原字符串右对齐,前面使用 0 填充。
# 使用语法:str.zfill (width)
double_str = "我想通过0填充让自己变强"
double_str.zfill(20)
'00000000我想通过0填充让自己变强'
join(seq),以指定字符串作为拼接字符,将 seq 中所有的元素(必须是字符串类型),拼接为一个新的字符串。
# 使用语法:"[chars]".join(seq)
# 尝试:拼接对象包含非字符串类型会报错
seq_list =["我想", "合并", "自己", 1]
"".join(seq_list)
# 用法一:不指定拼接字符,默认使用空字符
seq_list =["我想", "合并", "自己"]
"".join(seq_list)
'我想合并自己'
# 用法二:指定拼接字符【***】
"***".join(seq_list)
'我想***合并***自己'
maketrans(input, out),创建字符映射的转换表,第一个字符串参数,表示需要转换的字符,第二个字符串参数表示转换的目标。
# 使用语法:str.maketrans(input, out)
# 注意:两个字符串的长度必须相同,否则会报如下错误。
input_str = "预备开始,1234567"
out_str = "哆来咪发唆啦西"
tran_str = str.maketrans(input_str, out_str)
# 正确的使用方式
input_str = "1234567"
out_str = "哆来咪发唆啦西"
tran_str = str.maketrans(input_str, out_str)
waiter_tran = "预备开始,1234567"
waiter_tran.translate(tran_str)
'预备开始,哆来咪发唆啦西'
总结¶
通用类自建函数中, replace、join、strip、count、split、index、len、find 比较常用。
通用类自建函数支持链式调用,如处理字符串中空字符串和换行符,我们先使用 replace 处理空字符串,再使用 strip 处理换行符,可直接在后面使用
.链式调用。
double_str = " 我是等待链式 调用处理的字符串 \n"
double_str.replace(" ", "").strip()
'我是等待链式调用处理的字符串'
index、find 效果是一样的,但是 find 有容错机制,使用时优先选择。
今天先介绍通用类自建函数的相关操作,后续将介绍其他类函数的相关操作。
1.2 一文搞定 Python 字符串操作(下)¶
前言¶
前面介绍了通用类自建函数的相关操作,详细内容请前往一文搞定 Python 字符串操作(上)阅读。
今天介绍一下英文单词类、判断类、编码类、以及其他类自建函数的相关操作,并配上相关代码,便于理解、吸收。
单词类¶
capitalize(),将字符串的首字母转换为大写。
# 使用语法:str.capitalize()
>>> double_str = "my name is kele"
>>> double_str.capitalize()
'My name is kele'
title(),将字符串中所有单词的首字母转换为大写。
# 使用语法:str.title()
>>> double_str = "my name is kele"
>>> double_str.title()
'My Name Is Kele'
upper(),将字符串中的小写字母全部转换为大写。
# 使用语法:str.upper()
>>> double_str = "my name is kele"
>>> double_str.upper()
'MY NAME IS KELE'
lower(),将字符串中所有大写字母转换为小写。
# 使用语法:str.lower()
>>> double_str = "MY NAME IS KELE"
>>> double_str.lower()
'my name is kele'
swapcase(),将字符串中的大写字母转换为小写,小写字母转换为大写。
# 使用语法:str.swapcase()
>>> double_str = "MY NAME is kele"
>>> double_str.swapcase()
'my name IS KELE'
max(str),返回字符串 str 中最大的字母。
# 使用语法:max(str)
>>> double_str = "my name is kele"
>>> max(double_str)
'y'
min(str),返回字符串 str 中最小的字母。
# 使用语法:min(str)
>>> double_str = "double"
>>> min(double_str)
'b'
判断类¶
startswith(substr, beg=0,end=len(string)),判断字符串是否是以指定子字符串 substr 开头,是则返回 True,否则返回 False。若指定 beg 和 end 值,则在指定范围内判断。
# 使用语法:str.startswith(substr, beg=0,end=len(string))
# 用法一:不指定范围
>>> double_str = "my name is kele"
>>> double_str.startswith("my")
True
>>> double_str.startswith("your")
False
# 用法二:指定范围
>>> double_str.startswith("my", 2, 6)
False
endswith(suffix, beg=0, end=len(string)),判断字符串是否以指定子字符串 suffix 结束,是则返回 True,否则返回 False。若指定 beg 和 end 值,则在指定范围内判断。
# 使用语法:str.endswith(suffix, beg=0,end=len(string))
# 用法一:不指定范围
>>> double_str = "my name is kele"
>>> double_str.endswith("kele")
True
>>> double_str.endswith("xuebi")
False
# 用法二:指定范围
>>> double_str.endswith("kele", 0, 6)
False
isdigit(),判断字符串是否只包含数字,是则返回 True, 否则返回 False。
# 使用语法:str.isdigit()
>>> double_str = "1234567"
>>> double_str.isdigit()
True
>>> double_str = "1234567a"
>>> double_str.isdigit()
False
isalnum(),判断字符串是否至少有一个字符并且只包含字母、数字或字母和数字,是则返回 True,否则返回 False。
# 使用语法:str.isalnum()
# 空字符判断
>>> double_str = ""
>>> double_str.isalnum()
False
# 仅包含字母判断
>>> double_str = "abcdefg"
>>> double_str.isalnum()
True
# 仅包含数字判断
>>> double_str = "1234567"
>>> double_str.isalnum()
True
# 仅包含字母和数字判断
>>> double_str = "1234567a"
>>> double_str.isalnum()
True
# 包含标点判断
>>> double_str = "1234567a...."
>>> double_str.isalnum()
False
isalpha(),判断字符串是否至少有一个字符,并且全为字母,是则返回 True, 否则返回 False,中文也被视为字母字符。
# 使用语法:str.isalpha()
# 空字符判断
>>> double_str = ""
>>> double_str.isalpha()
False
# 仅包含字母判断
>>> double_str = "abcdefg"
>>> double_str.isalpha()
True
# 仅包含数字判断
>>> double_str = "abcdefg1"
>>> double_str.isalpha()
False
islower(),判断字符串是否至少包含一个字母,并且字母全为小写,是则返回 True,否则返回 False。
# 使用语法:str.islower()
# 空字符、不包含字母判断
>>> double_str = ""
>>> double_str.islower()
False
>>> double_str = "1234567"
>>> double_str.islower()
False
# 包含大写字母判断
>>> double_str = "Abcdefg"
>>> double_str.islower()
False
# 包含字母全为小写判断
>>> double_str = "abcdefg123456"
>>> double_str.islower()
True
isupper(),判断字符串是否至少包含一个字母,并且字母全为大写,是则返回 True,否则返回 False。
# 使用语法:str.isupper()
# 空字符、不包含字母判断
>>> double_str = ""
>>> double_str.isupper()
False
>>> double_str = "1234567"
>>> double_str.isupper()
False
# 包含小写字母判断
>>> double_str = "ABCDEFg"
>>> double_str.isupper()
False
# 包含字母全为大写判断
>>> double_str = "ABCDEFG123456"
>>> double_str.isupper()
True
istitle(),判断字符串中所有英文单词的首字母是全为大写,其他字母全为小写,是则返回 True,否则返回 False。
# 使用语法:str.istitle()
# 空字符、不包含字母判断
>>> double_str = ""
>>> double_str.istitle()
False
>>> double_str = "1234567"
>>> double_str.istitle()
False
# 包含小写字母判断
>>> double_str = "ABCDEFg"
>>> double_str.istitle()
False
# 包含字母全为大写判断
>>> double_str = "ABCDEFG123456"
>>> double_str.istitle()
True
isnumeric(),判断字符串是否只包含数字,是则返回 True,否则返回 False。数字可以是: Unicode 数字,全角数字(双字节),罗马数字,汉字数字。
# 使用语法:str.isnumeric()
# 空字符判断
>>> double_str = ""
>>> double_str.isnumeric()
False
# 包含非数字判断
>>> double_str = "1234567a"
>>> double_str.isnumeric()
False
# 全为阿拉伯数字、中文数字判断
>>> double_str = "1234567"
>>> double_str.isnumeric()
True
>>> double_str = "123一二"
>>> double_str.isnumeric()
True
isdecimal(),判断字符串是否只包含十进制数字,是则返回 True,否则返回 False。
# 使用语法:str.isdecimal()
# 空字符判断
>>> double_str = ""
>>> double_str.isdecimal()
False
# 包含非十进制数字判断
>>> double_str = "1234567a"
>>> double_str.isdecimal()
False
# 全为十进制数字判断
>>> double_str = "1234567"
>>> double_str.isdecimal()
True
isspace(),判断字符串是否只包含空白字符,是则返回 True,否则返回 False。
# 使用语法:str.isdecimal()
# 空字符判断
>>> double_str = ""
>>> double_str.isspace()
False
# 空格字符判断
>>> double_str = " "
>>> double_str.isspace()
True
# 换行符、制表符、回车符判断
>>> double_str = "\n\t\r"
>>> double_str.isspace()
True
编码类¶
encode(encoding='UTF-8',errors='strict'),以 encoding 指定的编码格式编码字符串,默认为
utf-8,如果出错默认报一个ValueError 的异常,除非 errors 指定的是ignore或者replace。
# 使用语法:str.encode(encoding='UTF-8',errors='strict')
>>> double_str = "utf-8编码"
>>> double_str.encode()
b'utf-8\xe7\xbc\x96\xe7\xa0\x81'
>>> double_str = "gbk编码"
>>> double_str.encode(encoding="gbk")
b'gbk\xb1\xe0\xc2\xeb'
bytes.decode(encoding="utf-8", errors="strict"),处理使用指定编码格式编码后的字符串,其中
bytes可通过字符串编码 str.encode() 来获取。
# 使用语法:bytes.encode(encoding='UTF-8',errors='strict')
>>> double_str = "utf-8编码"
>>> utf8_encode = double_str.encode()
>>> utf8_encode.decode()
'utf-8编码'
>>> double_str = "gbk编码"
>>> gbk_encode = double_str.encode("gbk")
>>> gbk_encode.decode("gbk")
'gbk编码'
其他类¶
expandtabs(tabsize=8),把字符串 string 中的水平制表符
tab 符号转为空格,默认为 8 个空格 。
# 使用语法:str.expandtabs()
# 不指定空格数,默认为 8
>>> double_str = "\t"
>>> double_str.expandtabs()
' '
# 指定空格数为 4
>>> double_str.expandtabs(tabsize=4)
' '
translate(table, deletechars=""),根据 str 给出的表 (包含 256 个字符)转换 string 的字符,bytes 类型的数据还支持,过滤 deletechars 参数中的字符。
# 使用语法一:str.translate(table)
>>> input_str = "1234567"
>>> out_str = "哆来咪发唆啦西"
>>> table = str.maketrans(input_str, out_str)
>>> double_str = "预备开始,1234567"
>>> double_str.translate(table)
'预备开始,哆来咪发唆啦西'
# 使用语法二:bytes.translate(table[, delete])
>>> input_str = b"1234567"
>>> out_str = b"abcdefg"
>>> table = bytes.maketrans(input_str, out_str)
>>> double_str = b"1234567"
>>> double_str.translate(table, b"7")
b'abcdef'
总结¶
单词类函数中,title、upper、lower、 capitalize 较为常用。
判断类函数,是处理判断相关业务逻辑的好帮手,其中 startswith、endswith 能帮我们精确判断出以特定字符开头、结尾的相关数据,如固定头文件数据、文件的后缀名判断等。
编码类函数在工作也比较常用,如网络爬虫中的页面数据解析、外部 API 调用编码处理等,注意解码、编码的编码方式必须一致。
至此,Python 字符串自建函数的相关操作已经全部介绍完毕,有描述不当之处,欢迎在留言区批评、指正,也可加我微信进一步沟通。
1.3 Python 字符串,劳动节前夕加餐¶
前言¶
前面介绍了 Python 字符串自建函数的相关操作,详细内容请前往一文搞定 Python 字符串操作(上)、一文搞定 Python 字符串操作(下)阅读。
今天介绍一下 Python 字符串转义字符、运算符、以及格式化输出的相关知识,并附上相关案例代码,便于学习、理解。
转义字符¶
Python 用反斜杠 \
转义字符,赋予字符新的含义。虽然转义字符由多个字符组成,但在 Python
中会将其视为一个字符,具体说明请参考下表:
符号 |
说明 |
|---|---|
|
单引号 |
|
双引号 |
\a |
发出系统响铃声 |
\0 |
空字符 |
\n |
换行符 |
\r |
回车符 |
\t |
横向制表符(Tab) |
\v |
纵向制表符 |
\f |
换页符 |
\ |
反斜杠 |
\o |
八进制表示符 |
\x |
十六进制表示符 |
\b |
退格符(Backspace) |
我们选择几个转义字符演示一下效果
1、单引号、双引号
>>> print("my \' name is kele")
my ' name is kele
>>> print("my \" name is kele")
my " name is kele
2、响铃符,注意并非喇叭发声而是蜂鸣器,现在的计算机基本都不带了,所以响铃不一定有效
>>> print("my \a name is kele")
my name is kele
3、空字符、换行符、回车符
# 空字符
>>> print("my \0 name is kele")
my name is kele
# 换行符
>>> print("my \n name is kele")
my
name is kele
# 回车符
>>> print("my \r name is kele")
my
name is kele
4、横向制表符、反斜杠
# 横向制表符,默认为 4 个空格
>>> print("my\tname is kele")
my name is kele
# 回车符
>>> print("my \\r name is kele")
my \r name is kele
运算符¶
字符串运算符与相关描述,请参考下表:
符号 |
说明 |
|---|---|
|
拼接字符串 |
* |
重复输出字符串 |
[] |
通过索引取字符串元素 |
[:] |
截取部分字符串,遵循左闭右开原则 |
in |
成员运算符,判断字符串是否包含元素 |
not in |
成员运算符,与 in 相反 |
r/R |
原始字符串,让转义字符失效 |
% |
格式化字符串 |
1、使用 + 拼接 字符串。
>>> before_str = "Hi,"
>>> after_str = "my name is kele"
>>> splicing_str = before_str + after_str
>>> splicing_str
'Hi,my name is kele'
2、使用 * 重复输出字符串。
>>> double_str = "Hi"
>>> double_str * 5
'HiHiHiHiHi'
3、使用索引值获取字符串元素,索引从 0 开始。
>>> double_str = "my name is kele"
>>> double_str[0] # 获取字符串第 1 个元素
'm'
>>> double_str[4] # 获取字符串第 5 个元素
'a'
4、使用索引值截取部分字符串,索引从 0 开始。
>>> double_str = "my name is kele"
>>> double_str[0:2] # 截取字符串第 1~2 个元素
'my'
>>> double_str[2:4] # 截取字符串第 3~4 个元素
' n'
5、使用 in & not in 判断字符串是否包含元素。
>>> double_str = "my name is kele"
>>> "kele" in double_str
True
>>> "xuebi" in double_str
False
>>> "xuebi" not in double_str
True
>>> "kele" not in double_str
False
6、使用 r & R 输出原始字符串,让转义字符失效。
# 未使用时,会输出空行
>>> print("\n")
>>> print(r"\n")
\n
>>> print(R"\n")
\n
格式化输出¶
字符串格式化输出与相关描述,请参考下表:
符号 |
说明 |
|---|---|
%c |
格式化字符及其ASCII码 |
%s |
格式化字符串 |
%d |
格式化整数 |
%o |
格式化无符号八进制数 |
%x |
格式化无符号十六进制数 |
%X |
格式化无符号十六进制数(大写) |
%f |
格式化浮点数字,可指定小数点后的精度 |
%e |
用科学计数法格式化浮点数 |
%E |
作用同 %e,用科学计数法格式化浮点数 |
%g |
%f 和 %e 的简写 |
%G |
%f 和 %E 的简写 |
format() |
格式化字符串的函数,Python 2.6 开始 |
f-string |
字面量格式化字符串,Python 3.6 开始 |
格式化操作符,常用辅助参数可参考下表:
辅助参数 |
描述 |
|---|---|
m 为最小宽度,n为小数点位数 |
|
|
左对齐 |
|
添加符号 |
# |
八进制添加 |
0 |
显示数字时使用 |
1、使用 %c 格式化字符及其ASCII码。
>>> "%c" % 97
'a'
>>>"%c%c%c" % (97, 98, 99)
'abc'
2、使用 %s 格式化输出字符串。
>>> "Hi, my name is %s" % "kele"
'Hi, my name is kele'
>>> "%s, my name is %s" % ("Hi", "kele")
'Hi, my name is kele'
3、使用 %d 格式化输出整数。
>>> "1 + 1 = %d" % 2
'1 + 1 = 2'
>>> "%d + %d = %d" % (1, 1, 2)
'1 + 1 = 2'
>>> "%5d" % 8 # 输出宽度为 5 的字符
' 8'
>>> "%-5d" % 8 # 左对齐
'8 '
>>> "%+d" % 8 # 显示整数符号
'+8'
>>> "%05d" % 8 # 使用 0 取代空格
'00008'
4、使用 %o 格式化无符号八进制数。
>>> "%o" % 16
'20'
>>> "%#o" % 16 # 添加八进制符号
'0o20'
5、使用 %x 或 %X 格式化无符号十六进制数。
>>> "%x" % 16
'10'
>>> "%X" % 16
'10'
>>> "%#x" % 16 # 添加十六进制符号
'0x10'
>>> "%#X" % 16 # 添加十六进制符号
'0X10'
6、使用 %f 格式化浮点数字,可指定小数点后面的精度。
>>> "%f" % 168.888
'168.888000' # 小数点后默认保留 6 位小数
>>> "%3.1f" % 168.888
'168.9' # 总宽度为3, 保留 1 位小数
>>> "%.2f" % 168.888
'168.89' # 保留 2 位小数
7、使用 %e 或 %E 用科学计数法格式化浮点数。
>>> "%e" % 168.888
'1.688880e+02'
>>> "%E" % 168.888
'1.688880E+02'
8、使用 %g 或 %G 格式化浮点数,根据值的大小选择合适的格式符。
>>> "%g" % 168.888
'168.888'
>>> "%g" % 1688888.888
'1.68889e+06'
>>> "%G" % 1688888.888
'1.68889E+06'
9、format 函数,通过 {} 和 : 来代替以前的
%,其中字符串操作使用大括号,数字操作使用冒号,本文以字符串为例。
# 不指定位置,默认按顺序匹配
>>> 'Hi my {} is {}'.format("name", "kele")
'Hi my name is kele'
# 指定位置,按位置匹配
>>> '{0} {1} {0}'.format("kele", "xuexi")
'kele xuexi kele'
# 文件目录拼接
>>> '{0}\\{1}\\{0}'.format("Desktop", "Python", "kele")
'Desktop\\Python\\Desktop'
10、f-string 格式化字符串以 f
开头,后面接字符串,字符串中的表达式用大括号 {}
包起来,可替换变量或表达式计算后的值。
# 替换变量
>>> name = "kele"
>>> f"my name is {name}"
'my name is kele'
# 替换表达式
>>> f"{1+1}"
'2'
格式化输出案例之打印三角形¶
for i in range(5):
for j in range(0, 5 - i):
print(end=" ")
for k in range(5 - i, 5):
print("*", end=" ")
print("")
# 效果如下:
*
* *
* * *
* * * *
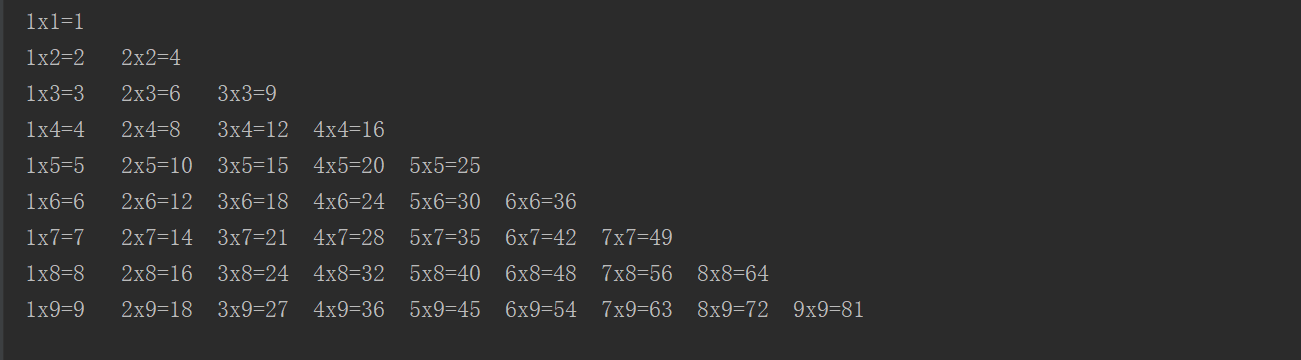
格式化输出案例之打印九九乘法表
for i in range(1, 10):
for j in range(1, i+1):
print('{}x{}={}\t'.format(j, i, i*j), end='')
print()
效果如下:
总结¶
1、转义字符中,换行符、回车符、反斜杠、制表符较为常用,使用 r 或者
R 可取消其转义功能。
2、运算符都比较常用,其中 in 和 not in
在处理字符串时常用于判断,能够帮助我们清洗一部分数据。
3、格式化输出较多,建议逐个进行尝试,其中 format
函数功能十分强大,工作中十分常用,
它在数字格式化方面的应用也较为丰富,它还可接收参数,甚至其参数可以是函数对象。
4、文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言去指正,字符串相关的有趣案例也可进行分享。
1.4 列表(List) | Python 最常用的数据结构之一¶
列表简介¶
列表 (List) 是 Python
中最基本的数据类型之一,列表中的每个元素均会分配一个数字,用以记录位置,我们称之为
索引 (Indexes),索引值从 0 开始,依次往后计数。
列表使用中括号- [] 包裹,元素之间使用逗号- ,
分隔,其元素可以是数字、字符串、列表等其他任何数据类型。
列表同样支持索引、更新、删除、嵌套、拼接、成员检查、截取、追加、扩展、排序等相关操作,下面我们通过案例来学习。
初识列表¶
使用中括号定义一个空列表
>>> def_list = []
>>> def_list
[]
>>> type(def_list) # type 查看数据类型
<class 'list'>
使用内置方法
list()定义一个空列表
>>> def_list = list()
>>> def_list
[]
>>> type(def_list) # type 查看数据类型
<class 'list'>
使用索引获取列表元素
>>> def_list = ["my", "name", "is", "kele"]
>>> def_list[0] # 取第一个元素
'my'
>>> def_list[-1] # -1 表示取最后一个
'kele'
>>> def_list[5] # 超出索引值会报错
Traceback (most recent call last):
File "<input>", line 1, in <module>
IndexError: list index out of range
通过索引更新列表元素
>>> def_list = ["my", "name", "is", "kele"]
>>> def_list[-1] = "xuebi" # 更新对应索引元素的值
>>> def_list
['my', 'name', 'is', 'xuebi']
使用
del语句删除列表元素
>>> def_list = ["my", "name", "is", "kele"]
>>> del def_list[0] # 删除第一个元素
>>> def_list
['name', 'is', 'kele']
>>> def_list = ["my", "name", "is", "kele"]
# 删除第一个元素 "my"
# 再删除新列表的第二个元素 "is"
>>> del def_list[0], def_list[1]
>>> def_list
['name', 'kele']
列表也可嵌套
>>> nesting_list = ["my", "name", ["is", "kele"]]
>>> type(nesting_list)
<class 'list'>
>>> nesting_list[2]
['is', 'kele']
# 怎么获取嵌套列表中的元素?
>>> nesting_list[2][0]
'is'
基础操作符¶
列表基础操作符可参照下表:
符号 |
说明 |
|---|---|
|
列表拼接 |
* |
重复元素 |
in / not in |
成员判断 |
[] |
索引取值 |
[index:index] |
列表截取 |
使用
+拼接列表
>>> def_list1 = ["my", "name"]
>>> def_list2 = ["is", "kele"]
>>> def_list1 + def_list2
['my', 'name', 'is', 'kele']
使用
*重复列表元素
>>> ["repeat two"] * 2
['repeat two', 'repeat two']
判断元素是否在列表中,是返回 True,否则返回 False
>>> def_list = ["my", "name", "is", "kele"]
>>> "kele" in def_list
True
>>> "xuebi" in def_list
False
>>> "kele" not in def_list
False
>>> "xuebi" not in def_list
True
使用索引取值
>>> def_list = ["my", "name", "is", "kele"]
>>> def_list[-1] # -1 表示取最后一个
'kele'
>>> def_list[5] # 超出索引值会报错
Traceback (most recent call last):
File "<input>", line 1, in <module>
IndexError: list index out of range
使用
:截取列表,遵循左开右闭原则
>>> def_list = ["Hi", "my", "name", "is", "kele"]
# 截取第一至第二个元素(不包括第二个元素)
>>> def_list[1:2]
['my']
# 截取第一至第四个元素(不包括第四个元素)
>>> def_list[1:4]
['my', 'name', 'is']
# 超出索引值并不会报错
>>> def_list[1:10]
['my', 'name', 'is', 'kele']
# 全列表截取(复制列表)
>>> def_list[:]
['my', 'name', 'is', 'kele']
# 指定步长,截取列表
# 步长为 2 ,表示每两个元素取一个元素
>>> def_list[0:5:2]
['Hi', 'name', 'kele']
# 怎么反转列表?
>>> def_list[::-1]
['kele', 'is', 'name', 'my', 'Hi']
列表基础函数¶
列表基础函数可参照下表:
函数 |
说明 |
|---|---|
len(list) |
计算列表的长度 |
max(list) |
返回列表中最大的元素 |
min(list) |
返回列表中最小的元素 |
list(seq) |
将其他序列转换为列表 |
计算列表长度
>>> def_list = num_list = [1, 4, 3, 11, 7, 8, 15]
>>> len(num_list)
7
返回列表最大值、最小值
>>> def_list = num_list = [1, 4, 3, 11, 7, 8, 15]
>>> max(num_list)
15
>>> min(num_list)
1
将其他序列列转换为列表
>>> str_list = "Hi_kele"
>>> list(str_list)
['H', 'i', '_', 'k', 'e', 'l', 'e']
>>> num_list = "123456"
>>> list(num_list)
['1', '2', '3', '4', '5', '6']
# 数字类型为不可迭代对象,所以使用时会报错
>>> num_list = 123456
>>> list(num_list)
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: 'int' object is not iterable
列表自建方法¶
Python 中的 list
类提供了列表操作相关的自建方法,需要时直接调用即可。
使用
append方法给列表末尾追加元素
# 使用语法:list.append(obj)
>>> def_list = ["my", "name", "is", "kele"]
>>> def_list.append(1)
>>> def_list
['my', 'name', 'is', 'kele', '1']
使用
count统计某个元素在列表中出现的总次数
# 使用语法:list.count(obj)
>>> def_list = ["kele", "name", "is", "kele"]
>>> def_list.count("kele")
2
>>> def_list.count("name")
1
>>> def_list.count("xuebi")
0
使用
index方法寻找某个元素在列表中第一次出现的索引值
# 使用语法:list.index(obj)
>>> def_list = ["kele", "name", "is", "kele"]
>>> def_list.index("kele")
0
>>> def_list.index("name")
1
# 元素不在列表中会报错
>>> def_list.count("xuebi")
Traceback (most recent call last):
File "<input>", line 1, in <module>
ValueError: 'xuebi' is not in list
使用
insert方法在指定位置插入元素
# 使用语法:list.insert(index, obj)
>>> def_list = ["my", "name", "is", "kele"]
>>> def_list.insert(0, "python")
>>> def_list
['python', 'my', 'name', 'is', 'kele']
# 超出索引值不报错,将元素插入到列表末尾
>>> def_list.insert(10, "xuebi")
>>> def_list
['python', 'my', 'name', 'is', 'kele', 'xuebi']
使用
pop方法弹出列表中的某个元素,默认弹出最后一个元素
# 使用语法:list.pop(index=-1)
>>> def_list = ["my", "name", "is", "kele"]
# 返回弹出的元素
>>> def_list.pop()
'kele'
>>> def_list
['my', 'name', 'is']
>>> def_list.pop(0)
'my'
>>> def_list
['name', 'is']
# 超出索引值会报错
>>> def_list.pop(10)
Traceback (most recent call last):
File "<input>", line 1, in <module>
IndexError: pop index out of range
使用
remove方法删除列表中的某个元素,默认删除第一次出现的元素
# 使用语法:list.remove(obj)
>>> def_list = ["kele", "name", "is", "kele"]
>>> def_list.remove("kele")
>>> def_list
['name', 'is', 'kele']
>>> def_list.remove("xuebi")
# 元素不存在会报错
Traceback (most recent call last):
File "<input>", line 1, in <module>
ValueError: list.remove(x): x not in list
使用
reverse方法反转列表
# 使用语法:list.reverse()
>>> def_list = ["my", "name", "is", "kele"]
>>> def_list.reverse()
>>> def_list
['kele', 'is', 'name', 'my']
使用
sort方法对列表进行排序,使用语法list.sort(cmp=None, key=None, reverse=False)参数说明:
cmp -- 可选参数,如果指定该参数,则使用该参数的方法进行排序。
key -- 主要用于比较元素,只有一个参数,指定可迭代对象中的一个元素进行排序。
reverse -- 排序规则,reverse = True 降序, reverse = False 升序(默认)。
# 使用语法:list.sort(cmp=None, key=None, reverse=False)
# 不指定参数,默认为降序
>>> def_list = ["my", "name", "is", "kele"]
>>> def_list.sort()
>>> def_list
['is', 'kele', 'my', 'name']
# 指定为升序
>>> def_list.sort(reverse=True)
>>> def_list
['name', 'my', 'kele', 'is']
# 指定可迭代对象中的一个元素进行排序
>>> def_list = ["my2", "name8", "is5", "keke9"]
# 按照序列的最后一个元素排序
>>> def key_func(seq):
... return seq[-1]
>>> def_list.sort(key=key_func)
>>> def_list
# 按照每个元素末尾的数字排序
['my2', 'is5', 'name8', 'keke9']
# 思考:怎么实现两种规则的排序,如既按照元素中的字母排序,又按照元素中的数字排序?
使用
extend方法扩展列表
# 使用语法:list.extend(seq)
>>> def_list1 = ["my", "name"]
>>> def_list2 = ["is", "kele"]
>>> def_list1.extend(def_list2)
>>> def_list1
['my', 'name', 'is', 'kele']
使用
copy方法复制列表
# 使用语法:list.copy()
>>> def_list = ["my", "name", "is", "kele"]
>>> def_list.copy()
['my', 'name', 'is', 'kele']
使用
clear方法清空列表元素
# 使用语法:list.clear()
>>> def_list = ["my", "name", "is", "kele"]
>>> def_list.clear()
>>> def_list
[]
列表扩展¶
使用大于号
>、小于号<、等于号==比较两个列表的大小。
"""比较原理:
从第一个元素开始比较,若相等,则继续比较,返回第一个不相等元素比较的结果。
若所有元素比较均相等,且列表长度一样则两列表相等,否则长度较大的列表大。
"""
# 判断两列表相等
>>> ["a", "b"] == ["a", "b"]
True
>>> ["a", "b"] == ["a", "c"]
False
# 判断两列表大于或者等小于
>>> ["a", "c"] > ["a", "b", "c"]
True
>>> ["a", "b"] < ["a", "b", "c"]
True
使用
and、or进行对列表表达式进行逻辑判断 。
"""判断原理:对表达式判断进行逻辑判断
1、and - 有假则为假
2、 or - 有真则为真
"""
# and
>>> ["a"] == ["a"] and ["a"] == ["a"]
True
>>> ["a"] == ["a"] and ["a"] == ["b"]
False
# or
>>> ["a"] == ["a"] or ["a"] == ["a"]
True
>>> ["a"] == ["a"] or ["a"] == ["b"]
True
总结¶
列表作为 Python 最基本的数据类型之一,在工作中十分常用,一般与其他数据类型搭配使用,用于构建数据结构。
定义列表可直接使用
[], 也可选择list()方法,个人偏向于前者。基础操作符中的列表截取、或称之为切片,很有意思,建议多探讨、研究。
使用
list()方法转换其他序列时,转换对象需为可迭代对象,否则会报错。自建方法均比较常用,索引的相关操作,需考虑索引值范围,调用方式有两种,一是使用关键字
list.方法(参数),二是使用定义的列表变量名.方法(参数),其原理都是调用Python中的list类中的方法,案例中使用后者。文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,列表相关的知识点也可进行分享。
1.5 Python 字典操作,母亲节加餐¶
字典简介¶
字典 (Dictionary) 是 Python
中常用的数据结构之一,它用于存放具有映射关系的数据,其灵活性极高,可存储任意类型的数据对象,它有时也被称作关联数组或哈希表。
字典以键值对 的形式存储数据,每个键值对以冒号 : 连接,
冒号左侧为键(key),右侧为值(value),且键与值都使用单引号
'' 或 双引号""包裹。
字典使用大括号- {} 包裹,键值对之间使用逗号- ,
分隔,与列表不同,字典中的元素是无序的。
字典支持更新、删除、嵌套、拼接、成员检查、追加、扩展、排序等相关操作,下面我们通过案例来学习。
初识字典¶
1、使用大括号定义一个空字典。
>>> def_dict = {}
>>> def_dict
{}
# type 查看数据类型
>>> type(def_dict)
<class 'dict'>
2、使用内置方法 dict() 定义一个空字典(推荐使用)。
>>> def_dict = dict()
>>> def_dict
{}
# type 查看数据类型
>>> type(def_dict)
<class 'dict'>
3、字典也可嵌套。
>>> def_dict = {"nesting": {"name": "kele"}}
# 怎么取嵌套字典中的元素
>>> def_dict["nesting"]["name"]
'kele'
4、字典特性之键必须唯一。
>>> def_dict = {"name": "kele", "name": "xuebi"}
>>> def_dict
# 若键不唯一,仅会记录最后一次的值
{'name': 'xuebi'}
5、字典特性之键必须不可变。
# Python 中数字、元组、字符串为不可变类型
# Python 中列表、字典、集合为可变类型
>>> def_dict = {"name": "kele"}
>>> def_dict = {1: "kele"}
>>> def_dict = {("name", "kele"): "kele"}
# 键为可变类型会报错
>>> def_dict = {["name", "kele"]: "kele"}
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: unhashable type: 'list'
字典基本操作¶
1、使用键获取字典中的值。
>>> def_dict = {"name": "kele", "hobby": "Python"}
# 获取 name 的 value
>>> def_dict["name"]
'kele'
# 获取 hobby 的 value
>>> def_dict["hobby"]
'Python'
# key 值不存在会报错
>>> def_dict["age"]
Traceback (most recent call last):
File "<input>", line 1, in <module>
KeyError: 'age'
2、使用 get 方法获取字典中的值。
>>> def_dict = {"name": "kele", "hobby": "Python"}
# 获取 name 的 value
>>> def_dict.get("name")
'kele'
# 获取 hobby 的 value
>>> def_dict.get("hobby")
'Python'
3、使用键更新字典中的值。
>>> def_dict = {"name": "kele"}
# key 存在则修改
>>> def_dict["name"] = "xuebi"
>>> def_dict
{'name': 'xuebi'}
# key 不存在则新增
>>> def_dict["age"] = 18
>>> def_dict
{'name': 'xuebi', 'hobby': 'Python', 'age': 18}
4、使用 del 语句删除字典元素。
>>> def_dict = {"name": "kele", "hobby": "Python"}
>>> del def_dict["hobby"]
>>> def_dict
{'name': 'kele'}
5、使用 in 、not in 判断指定 key 值是否在字典中,是则返回
True,否则返回 False。
>>> def_dict = {"name": "kele"}
# 字典是基于 key 值来判断的
>>> "name" in def_dict
True
>>> "name" not in def_dict
False
字典基础方法¶
字典基础方法可参照下表:
方法 |
说明 |
|---|---|
len(dict) |
计算字典键值对数量 |
str(dict) |
将字典转换为字符串 |
type(dict) |
查看数据类型 |
1、使用 len 方法计算字典长度。
>>> def_dict = {"name": "kele", "hobby": "Python"}
>>> len(def_dict)
2
2、使用 str 方法,将字典转换为字符串。
>>> def_dict = {"name": "kele"}
>>> str(def_dict)
"{'name': 'kele'}"
3、使用 type 方法查看数据类型。
>>> def_dict = {"name": "kele"}
>>> type(def_dict)
# 字典为 dict 类型
<class 'dict'>
字典内置方法¶
Python 中的 dict
类提供了字典操作相关的内置方法,使用时直接调用即可,下面按照类中方法定义的顺序演示。
1、使用 clear 方法清空字典。
# 使用语法:dict.clear()
>>> def_dict = {"name": "kele"}
>>> def_dict.clear()
>>> def_dict
{}
2、使用 copy 方法复制字典。
# 使用语法:dict.copy()
>>> def_dict = {"name": "kele"}
>>> def_dict.copy()
{'name': 'kele'}
3、使用 fromkeys 方法,创建新字典,以序列 seq
中的元素作为键,以键对应的初始值 value 作为值。
# 使用语法:dict.fromkeys(seq[, value])
>>> seq = ('name', 'age')
# 不指定 value 值,默认为 None
>>> dict.fromkeys(seq)
{'name': None, 'age': None}
# 不指定 value 值
>>> dict.fromkeys(seq, "kele")
{'name': 'kele', 'age': 'kele'}
4、使用 get 方法,获取字典元素。
# 使用语法:dict.get(key, default=None)
>>> def_dict = {"name": "kele"}
>>> def_dict.get("name")
'kele'
# key 值不存在不会报错
>>> print(def_dict.get("age"))
None
# get 方法还可指定默认值
>>> def_dict.get("age", 18)
18
5、使用 items 方法,获取字典所有键值对数据。
# 使用语法:dict.items()
>>> def_dict = {"name": "kele"}
>>> def_dict.items()
# 返回一个 dict_items 对象,可转为列表
dict_items([('name', 'kele')])
>>> list(def_dict.items())
[('name', 'kele')]
6、使用 keys 方法,获取字典所有的键。
# 使用语法:dict.keys()
>>> def_dict = {"name": "kele", "hobby": "Python"}
>>> def_dict.keys()
# 返回一个 dict_keys 对象,可转为列表
dict_items([('name', 'kele')])
>>> list(def_dict.keys())
['name', 'hobby']
7、使用 pop 方法,删除字典指定键的键值对数据,返回删除键对应的值。
# 使用语法:dict.pop(key[,default])
>>> def_dict = {"name": "kele", "hobby": "Python"}
>>> def_dict.pop()
# 必须指定 key 值,否则报错
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: pop expected at least 1 arguments, got 0
# 指定 key 值,返回其对应的值
>>> def_dict.pop("hobby")
'Python'
# key 不存在会报错
>>> def_dict.pop("age")
Traceback (most recent call last):
File "<input>", line 1, in <module>
KeyError: 'age'
# key 不存在,给定默认值可避免报错
>>> def_dict.pop("age", 18)
18
8、使用 popitem 方法,删除字典中最后一个键值对数据并将其返回。
# 使用语法:dict.popitem()
>>> def_dict = {"name": "kele", "hobby": "Python"}
>>> def_dict.popitem()
('hobby', 'Python')
# 原字典变成了这样
>>> def_dict
{'name': 'kele'}
# 再调用一次
>>> def_dict.popitem()
('name', 'kele')
# 字典为空时调用会报错
>>> def_dict.popitem()
Traceback (most recent call last):
File "<input>", line 1, in <module>
KeyError: 'popitem(): dictionary is empty'
9、使用 setdefault 方法,获取字典元素,与 get 方法类似。
# 使用语法:dict.setdefault(key, default=None)
>>> def_dict = {"name": "kele"}
>>> def_dict.setdefault("name")
'kele'
# key 值不存在不会报错
>>> print(def_dict.setdefault("age"))
None
# setdefault 方法也可指定默认值
>>> def_dict.setdefault("age", 18)
18
# 那它与 get 方法有什么区别呢?
>>> def_dict = {"name": "kele"}
# key 不存在时,get 方法不会进行新增操作
>>> def_dict.get("age", 18)
>>> def_dict
{"name": "kele"}
# key 不存在时,setdefault 方法会进行新增操作
>>> def_dict.setdefault("age", 18)
>>> def_dict
{'name': 'kele', 'age': 18}
10、使用 update 方法,更新字典。
# 使用语法:dict.update(dict2)
>>> def_dict = {"name": "kele"}
>>> def_dict2 = {"age": "18"}
>>> def_dict.update(def_dict2)
# 将 def_dict2 中的数据更新至 def_dict 中
>>> def_dict
{'name': 'kele', 'age': '18'}
11、使用 values 方法,获取字典中所有的值。
# 使用语法:dict.values()
>>> def_dict = {"name": "kele", "hobby": "Python"}
>>> def_dict.values()
# dict_values(['kele', 'Python'])
>>> type(def_dict.values())
# 返回一个 dict_values 对象,可转为列表
<class 'dict_values'>
>>> list(def_dict.keys())
['kele', 'Python']
字典扩展¶
1、使用 sorted 函数对字典的键或值进行排序。
>>> def_dict = {"a": 2, "c": 1, "b":3}
# 直接调用,默认对键进行排序
# 返回排序后键组成的列表
>>> sorted(def_dict)
['a', 'b', 'c']
# 使用匿名函数 lambda 按照键排序
>>> sorted(def_dict.items(), key=lambda x:x[0])
[('a', 2), ('b', 3), ('c', 1)]
# 默认为升序,指定为降序
>>> sorted(def_dict.items(), key=lambda x:x[0], reverse=True)
# 使用匿名函数 lambda 按照值排序
>>> sorted(def_dict.items(), key=lambda x:x[1])
[('c', 1), ('a', 2), ('b', 3)]
# 原字典并不会改变
>>> def_dict
{"a": 2, "c": 1, "b":3}
2、使用 sorted 函数对字典组成的列表,进行多个键的排序。
>>> def_list = [{ "name" : "kele", "age" : 18},
{ "name" : "xuebi", "age" : 7 },
{ "name" : "tea", "age" : 20 },
{ "name" : "wine" , "age" : 20}]
# 先按 age 排序,再按 name 排序
# 若 age 相同,再按 name 排序
>>> sorted(def_list,key=lambda x:(x["age"], x["name"]))
[{'name': 'xuebi', 'age': 7},
{'name': 'kele', 'age': 18},
{'name': 'tea', 'age': 20},
{'name': 'wine', 'age': 20}]
总结¶
字典是 Python 中除列表以外, 最灵活的数据结构,工作中也十分常用。
定义字典可直接使用大括号-
{}, 也可选择dict()方法,后者更加规范。字典内置方法均比较常用,其中
get方法与setdefault方法类似,区别在于,当字典的键不存在时,后者会新增元素,前者不会。文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,也可分享字典相关的知识。
Python 系列相关文章已全部更新至个人博客:kelepython.rtfd.io,欢迎前往阅读。
为了便于沟通交流,我已创建微信学习交流群,欢迎在后台回复
加群加入我们。最后,祝所有伟大的母亲节日快乐、身体健康、工作顺利!
1.6 元组(Tuple) | 不可改变的 Python 数据类型¶

元组简介¶
元组 (Tuple) 是 Python
中基本数据结构之一,与列表类似,但元组中的元素不允许被修改,因此元组也被称作只读列表。
元组使用小括号- () 包裹,元素之间使用逗号- ,
分隔,元组中的元素可以是字符串、数字、列表、元组等其他数据类型。
元组不支持修改,但支持索引、拼接、成员检查、重复等相关操作,下面我们通过案例来学习。
初识元组¶
1、使用小括号定义一个空元组。
>>> def_tuple = ()
>>> def_tuple
()
# type 查看数据类型
>>> type(def_tuple)
<class 'tuple'>
2、使用 tuple() 方法定义一个空元组。
>>> def_tuple = tuple()
>>> def_tuple
()
# type 查看数据类型
>>> type(def_tuple)
<class 'tuple'>
3、使用索引获取元组元素。
>>> def_tuple = ("kele", "tea")
>>> def_tuple[0]
'kele'
4、元组也可嵌套。
>>> def_tuple = ("kele", ("xuebi", "tea"))
>>> def_tuple[1]
("xuebi", "tea")
# 怎么取嵌套元组中的元素?
>>> def_tuple[1][0]
'xuebi'
5、元组特性之元素不允许被修改,但其元素的元素为可变类型时则支持修改。
>>> def_tuple = ("kele", "tea")
>>> def_dict[0] = "xuebi"
# 试图修改元组中的元素会报错
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
# 元组第二个元素是一个列表,可直接通过索引修改
>>> def_tuple = ("kele", ["tea", "kele"])
>>> def_tuple[1][1] = "xuebi"
>>> def_tuple
('kele', ['tea', 'xuebi'])
6、元组特性之元素不能被删除,但可删除整个元组。
>>> def_tuple = ("kele", "tea")
>>> del def_tuple[0]
# 试图删除元组中的元素会报错
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: 'tuple' object doesn't support item deletion
# 使用 del 删除整个元组
>>> del def_tuple
7、元组特性之任何无符号的对象,以逗号分割,默认被视为元组。
>>> any_unsigned_objects = "kele", "age", 18
>>> any_unsigned_objects
('kele', 'age', 18)
>>> type(any_unsigned_objects)
<class 'tuple'>
元组基本操作符¶
操作符 |
说明 |
|---|---|
+ |
连接元组元素 |
* |
重复元组元素 |
in / not in |
成员判断 |
[index:index] |
元组切片 |
1、使用 + 连接元组元素。
>>> def_tuple1 = ("kele", "tea")
>>> def_tuple2 = ("xuebi", "coffee")
>>> def_tuple1 + def_tuple2
('kele', 'tea', 'xuebi', 'coffee')
2、使用 * 重复元组元素。
>>> def_tuple = ("kele", "tea")
>>> def_tuple * 2
('kele', 'tea', 'kele', 'tea')
3、使用 in 、not in 判断元素是否在元组中,是则返回 True ,
否则返回 False 。
>>> def_tuple = ("kele", "python")
>>> "kele" in def_tuple
True
>>> "python" not in def_tuple
False
4、使用 [:] 对元组进行切片,遵循左闭右开原则。
>>> def_tuple = ("Hi", "my", "name", "is", "kele")
# 截取第一至第三个元素(不包括第三个元素)
>>> def_tuple[0:2]
("Hi", "my")
# 超出索引值并不会报错
>>> def_tuple[0:10]
('Hi', 'my', 'name', 'is', 'kele')
# 全元组截取(复制元组)
>>> def_tuple[:]
('Hi', 'my', 'name', 'is', 'kele')
# 指定步长,截取列表
# 步长为 2 ,表示每两个元素取一个元素
>>> def_tuple[0:5:2]
('Hi', 'name', 'kele')
# 怎么反转元组?
>>> def_tuple[::-1]
('kele', 'is', 'name', 'my', 'Hi')
元组基础方法¶
元组基础方法可参照下表:
方法 |
说明 |
|---|---|
len(tuple) |
计算元组元素数量 |
max(tuple) |
返回元组中最大的元素 |
min(tuple) |
返回元组中最小的元素 |
type(tuple) |
查看数据类型 |
tuple(iterable) |
将可迭代对象转换为元组 |
1、使用 len 方法计算元组数量。
>>> def_tuple = ("kele", "python")
>>> len(def_tuple)
2
2、使用 max 方法,返回元组中最大的元素。
>>> def_tuple = (18, 8, 168)
>>> max(def_tuple)
168
3、使用 min 方法,返回元组中最小的元素。
>>> def_tuple = (18, 8, 168)
>>> min(def_tuple)
8
4、使用 type 方法查看数据类型。
>>> def_tuple = ("kele", "python")
>>> type(def_tuple)
<class 'tuple'>
5、使用 tuple 方法将可迭代对象转换为元组。
>>> def_list = ["kele", "python"]
>>> tuple(def_list)
('kele', 'python')
>>> type(tuple(def_list))
<class 'tuple'>
元组内置方法¶
Python 中的 tuple
类提供了元组操作相关的内置方法,由于元组仅有两个内置方法,这里再选择类中的部分
魔法方法 进行演示,下面按照类中方法定义的顺序演示。
1、使用 index 返回某一元素在元组中第一次出现的索引值。
# 使用语法:dict.index(obj)
>>> def_tuple = ("Hi", "kele", "python", "kele")
>>> def_dict.index("kele")
1
2、使用 count 方法统计某一元素在元组中出现的次数。
# 使用语法:dict.count(obj)
>>> def_tuple = ("Hi", "kele", "python", "kele")
>>> def_tuple.count("kele")
2
>>> def_tuple.count("xuebi")
0
3、使用 __add__ 方法在元组后面追加新的元组,与 + 类似。
# 使用语法:dict.__add__(tuple)
>>> def_tuple = ("Hi", "kele")
>>> def_tuple2 = ("python", "say")
>>> def_tuple.__add__(def_tuple2)
('Hi', 'kele', 'python', 'say')
4、使用 __contains__ 方法判断某一元素是否包含在元组中,是则返回
True , 否则返回 False ,与 in 、not in 类似。
# 使用语法:dict.__contains__(obj)
>>> def_tuple = ("Hi", "kele")
>>> def_tuple.__contains__("kele")
True
>>> def_tuple.__contains__("xuebi")
False
5、使用 __mul__ 方法重复元组元素,与 * 类似。
# 使用语法:dict.__mul__(num)
>>> def_tuple = ("Hi", "kele")
>>> def_tuple.__mul__(2)
('Hi', 'kele', 'Hi', 'kele')
>>> def_tuple.__contains__("xuebi")
False
元组扩展¶
1、使用 sorted 函数对元组进行排序。
>>> def_tuple = ("2c", "3a", "1b")
# 直接调用
# 返回排序后元素组成的列表
>>> sorted(def_tuple)
['1b', '2c', '3a']
# 使用匿名函数 lambda 按照元素的第一个字符排序
>>> sorted(def_tuple, key=lambda x:x[0])
['1b', '2c', '3a']
# 使用匿名函数 lambda 按照元素的第二个字符排序
>>> sorted(def_tuple, key=lambda x:x[1])
['3a', '1b', '2c']
# 原元组并不会改变
>>> def_tuple
('2c', '3a', '1b')
2、使用 sorted 函数对元组进行多规则的排序。
>>> def_tuple = ("2c", "3a", "1b", "3d")
# 先按第一个字符排序,若相同,再按第二个字符排序
>>> sorted(def_tuple,key=lambda x:(x[0], x[1]))
['1b', '2c', '3a', '3d']
总结¶
Python 中的元组与列表类似, 索引、切片等用法基本相同,但也存在一定差异,其不允许修改的特性,经常被用于定义、保存一些特定的数据。
定义元组可直接使用小括号-
(), 也可选择tuple()方法,在定义单元素元组时需要在末尾加上,,否则会引起误会。
# 习惯用法尝试
>>> def_tuple = ("kele")
>>> type(def_tuple)
# 居然不是元组,是字符串类型
<class 'str'>
>>> def_tuple = (1)
>>> type(def_tuple)
# 居然不是元组,是数字类型
<class 'int'>
# 正确用法
>>> def_tuple = ("kele", )
>>> type(def_tuple)
<class 'tuple'>
>>> def_tuple = (1, )
>>> type(def_tuple)
<class 'tuple'>
元组虽然不允许修改,但当其元素的子元素包含可变类型时,也是允许修改的,当然,也可通过连接、重复组成新的元组。
元组仅有两个内置方法,
tuple类中的其他魔法方法,大家可逐个进行尝试,对于效果一样的方法,使用时可自行选择。文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,也可分享元组相关的知识。
Python 系列相关文章已全部更新至个人博客:kelepython.rtfd.io,欢迎前往阅读。
为了便于沟通交流,我已创建微信学习交流群,欢迎在后台回复
加群加入我们。
1.7 集合 (Set) | 一山不容二虎的 Python 数据类型¶
集合简介¶
集合 (Set) 是 Python
中基本数据结构之一,与数学中的集合概念类似但又存在一定差异,集合中的元素唯一、且无序存储。
集合使用大括号 - {} 包裹,元素之间使用逗号 - ,
分隔,集合中的元素可以是字符串、数字、集合等其他任何不可变数据类型。
集合不支持索引、嵌套,也没有切片操作,但支持更新、删除等操作,并且可进行
并集 、交集、差集
等常见的集合操作,下面我们通过案例来学习。
集合初体验¶
1、使用 set() 方法定义一个空集合。
>>> def_set = set()
>>> def_set
set()
# type 查看数据类型
>>> type(def_set)
<class 'set'>
2、使用 {} 定义一个非空集合 。
# 之前介绍过 {} 用于定义空字典,故 {} 用于定义非空集合
>>> def_set = {"kele", "python"}
>>> def_set
{"kele", "python"}
# type 查看数据类型
>>> type(def_set)
<class 'set'>
3、集合特性之元素唯一。
>>> def_set = {"kele", "python", "kele"}
>>> def_set
{'kele', 'python'}
4、集合特性之元素无序存储。
>>> def_set = set(["1", "2", "3"])
# 元素为无序存储
>>> def_set
{'1', '3', '2'}
5、集合特性之不可通过索引获取元素,但可通过 for 循环获取。
>>> def_set = {"kele", "python"}
>>> def_set[0]
# 因集合是无序的,所以不能使用索引访问
Traceback (most recent call last):
File "<input>", line 1, in <module>
TypeError: 'set' object does not support indexing
# 使用 for 循环获取集合元素
>>> for set_element in def_set:
print(set_element)
kele
python
6、使用 in 、not in 判断元素是否在集合中,是则返回 True ,
否则返回 False 。
>>> def_set = ("kele", "python")
>>> "kele" in def_set
True
>>> "python" not in def_set
False
集合基础方法¶
集合基础方法可参照下表:
方法 |
说明 |
|---|---|
len(set) |
计算集合元素数量 |
max(set) |
返回集合中最大的元素 |
min(set) |
返回集合中最小的元素 |
type(set) |
查看数据类型 |
set(iterable) |
将可迭代对象转换为集合 |
1、使用 len 方法计算集合数量。
>>> def_set = {68, 8, 168}
>>> len(def_set)
3
2、使用 max 方法,返回集合中最大的元素。
>>> def_set = {68, 8, 168}
>>> max(def_set)
168
3、使用 min 方法,返回集合中最小的元素。
>>> def_set = {68, 8, 168}
>>> min(def_set)
8
4、使用 type 方法查看数据类型。
>>> def_set = {"kele","python"}
>>> type(def_set)
<class 'set'>
5、使用 set 方法将可迭代对象转换为集合。
>>> def_set = set(["kele", "python"])
>>> def_set
{'kele', 'python'}
>>> type(set(def_set))
<class 'set'>
集合内置方法¶
Python 中的 set
类提供了集合操作相关的内置方法,集合中还提供了部分操作符号与之对应,下面按照类中方法定义的顺序演示。
集合内置函数与集合操作符对于关系可参照下表:
方法 |
符号 |
说明 |
|---|---|---|
difference |
- |
计算差集 |
intersection |
& |
计算交集 |
issubset |
< |
子集判断 |
symmetric_difference |
^ |
计算对称差集 |
union |
| |
计算并集 |
1、使用 add 方法,给集合添加元素,若元素已存在,不做任何操作。
# 使用语法:set.add(obj)
# 必须给定 obj 参数
>>> def_set = {"kele","python"}
>>> def_set.add("kele")
# 元素已存在,不做任何操作
>>> def_set
{'python', 'kele'}
>>> def_set.add("xuebi")
>>> def_set
>>> {'xuebi', 'python', 'kele'}
2、使用 clear 方法清空集合。
# 使用语法:set.clear()
>>> def_set = {"kele","python"}
>>> def_set.clear()
>>> def_set
set()
3、使用 copy 方法 浅拷贝 复制一个新集合。
# 使用语法:set.copy()
>>> def_set = {"kele","python"}
>>> def_set.copy()
{'kele', 'python'}
4、使用 difference
方法,计算两个集合的差集,返回一个新集合,与集合运算符 - 效果相同。
# 使用语法:set1.difference(set2)
# 返回包含在 ste1 中,但不包含在 set2 中的元素
>>> def_set1 = {"kele","python"}
>>> def_set2 = {"kele","xuebi"}
>>> def_set1.difference(def_set2)
{'python'}
# 使用减号运算符计算两个集合的差值
>>> def_set1 - def_set2
{'python'}
# 也可使用集合一 减去 集合一与集合二的交集(后面会介绍)
>>> def_set1 - def_set2 & def_set1
{'python'}
5、使用 difference_update 方法,计算两个集合的差集,并直接从
def_set1 中移除两个集合都存在的元素。
# 使用语法:set1.difference_update(set2)
# 无返回值,直接从 def_set1 中移除两个集合都存在的元素
>>> def_set1 = {"kele","python"}
>>> def_set2 = {"kele","xuebi"}
>>> def_set1.difference_update(def_set2)
# 可以发现,已经移除了 "kele"
>>> def_set1
{'python'}
6、使用 discard 方法,删除集合中指定的元素,元素不存在也不会报错。
# 使用语法:set.discard(obj)
>>> def_set = {"kele","python"}
# 无返回值
>>> def_set.discard("kele")
>>> def_set1
{'python'}
# 元素不存在时不报错,不做任何操作
>>> def_set.discard("xuebi")
7、使用 intersection 方法,计算多个集合的交集,与集合运算符 &
效果相同。
# 使用语法:set1.intersection(set2,set3,...)
# 返回 set1、set2 的交集
>>> def_set1 = {"kele","python"}
>>> def_set2 = {"kele","xuebi"}
>>> def_set1.intersection(def_set2)
{'kele'}
# 返回 set1、set2、set3 的交集
>>> def_set3 = {"kele","tea"}
>>> def_set1.intersection(def_set2, def_set3)
{'kele'}
# 也可使用交集运算符计算集合的差值
>>> def_set1 & def_set2
{'kele'}
>>> def_set1 & def_set2 & def_set3
{'kele'}
8、使用 intersection_update 方法,计算多个集合的交集,并直接从
def_set1 中删除所有集合中都不重叠的元素。
# 使用语法:set1.intersection_update(set2,set3,...)
# 返回 set1、set2 的交集
>>> def_set1 = {"kele","python"}
>>> def_set2 = {"kele","xuebi"}
# 无返回值
>>> def_set1.intersection_update(def_set2)
# 已从 def_set1 中删除 "python"
>>> def_set1
{'kele'}
>>> def_set1.intersection(def_set2, def_set3)
{'kele'}
# 也可使用交集运算符计算集合的差值
>>> def_set1 & def_set2
{'kele'}
>>> def_set1 & def_set2 & def_set3
{'kele'}
9、使用 isdisjoint 方法,判断两个集合是否不包含相同的元素,是则返回
False ,否则返回 True 。
# 使用语法:set1.isdisjoint(set2)
>>> def_set1 = {"kele","python"}
>>> def_set2 = {"kele","xuebi"}
>>> def_set1.isdisjoint(def_set2)
False
>>> def_set3 = {"xuebi"}
>>> def_set1.isdisjoint(def_set3)
True
10、使用 issubset 方法,判断 set1 是否是 set2 的子集,是则返回
True ,否则返回 False 。
# 使用语法:set1.issubset(set2)
>>> def_set1 = {"kele"}
>>> def_set2 = {"kele","xuebi"}
# def_set1 是 def_set2 的子集
>>> def_set1.issubset(def_set2)
True
# def_set3 不是 def_set2 的子集
>>> def_set3 = {"xuebi"}
>>> def_set1.issubset(def_set3)
False
11、使用 issuperset 方法,判断 set1 是否是 set2 的 超集
,可理解为父集,是则返回 True ,否则返回 False 。
# 使用语法:set1.issuperset(set2)
>>> def_set1 = {"kele","xuebi"}
>>> def_set2 = {"kele"}
# def_set1 是 def_set2 的父集
>>> def_set1.issuperset(def_set2)
True
# def_set1 不是 def_set3 的父集
>>> def_set3 = {"kele","python"}
>>> def_set1.issuperset(def_set3)
False
12、使用 pop 方法,删除并返回集合中任意元素。
# 使用语法:set.pop()
>>> def_set = {"kele","python"}
>>> def_set.pop()
'kele'
>>> def_set.pop()
'python'
# 空集合调用会报错
>>> def_set.pop()
Traceback (most recent call last):
File "<input>", line 1, in <module>
KeyError: 'pop from an empty set'
13、使用 remove 方法,删除集合中某一元素。
# 使用语法:set.remove(obj)
>>> def_set = {"kele","python"}
# 无返回值
>>> def_set.remove("kele")
>>> def_set
{'python'}
# 元素不存在时会报错
>>> def_set.remove("xuebi")
Traceback (most recent call last):
File "<input>", line 1, in <module>
KeyError: 'xuebi'
14、使用 symmetric_difference
方法,删除两个集合中相同的元素,再取并集,即 对称差集 ,与集合运算符
^ 效果相同。
# 使用语法:set1.symmetric_difference(set2)
>>> def_set1 = {"kele","python"}
>>> def_set2 = {"kele","xuebi"}
# 先删除 kele ,再取并集
>>> def_set1.symmetric_difference(def_set2)
{'xuebi', 'python'}
# 也可使用运算符 ^ 计算集合的对称差
>>> def_set1 ^ def_set2
{'xuebi', 'python'}
15、使用 symmetric_difference_update
方法,取两个集合的对称差值,并在set1 中删除两个集合中相同的元素 。
# 使用语法:set1.symmetric_difference_update(set2)
>>> def_set1 = {"kele","python"}
>>> def_set2 = {"kele","xuebi"}
# 无返回值
>>> def_set1.symmetric_difference_update(def_set2)
>>> def_set1
{'python', 'xuebi'}
16、使用 union 方法,取多个集合的并集,与集合运算符 | 效果相同。
# 使用语法:set1.union(set2,set3,...)
# 返回 set1、set2 的并集
>>> def_set1 = {"kele","python"}
>>> def_set2 = {"kele","xuebi"}
>>> def_set1.union(def_set2)
{'python', 'kele', 'xuebi'}
# 返回 set1、set2、set3 的并集
>>> def_set3 = {"tea","xuebi"}
>>> def_set1.union(def_set2, def_set3)
{'kele', 'xuebi', 'python', 'tea'}
# 也可使用并集运算符计算集合的并集
>>> def_set1 | def_set2
{'python', 'kele', 'xuebi'}
>>> def_set1 | def_set2 | def_set3
{'kele', 'xuebi', 'python', 'tea'}
17、使用 update
方法,添加新的元素或集合到当前集合中,重复的元素会被忽略。
# 使用语法:set1.update(set2)
# 添加列表元素到当前集合中
>>> def_set1 = {"kele","python"}
# 无返回值
>>> def_set1.update(["tea", "xuebi"])
>>> def_set1
{'xuebi', 'python', 'tea', 'kele'}
# 添加集合元素到当前集合中
>>> def_set1 = {"kele","python"}
>>> def_set2 = {"tea","xuebi"}
# 无返回值
>>> def_set1.update(def_set2)
>>> def_set1
{'xuebi', 'python', 'tea', 'kele'}
集合应用¶
1、使用集合对字符串进行去重。
>>> def_str = "Hikelepython"
>>> def_set = set(def_str)
>>> def_set
{'l', 'h', 't', 'p', 'o', 'H', 'n', 'e', 'i', 'k', 'y'}
# 使用 join 方法连接字符串,这里暂时不考虑顺序
>>> "".join(def_set)
'lhtpoHneiky'
2、使用集合对列表进行去重。
>>> def_list = ["k", "e", "l", "e"]
>>> def_set = set(def_list)
>>> def_set
{'k', 'l', 'e'}
# 将集合转换成列表
>>> list(def_set)
['k', 'l', 'e']
3、使用集合对元组进行去重。
>>> def_tuple = ("k", "e", "l", "e")
>>> def_set = set(def_tuple)
>>> def_set
{'k', 'l', 'e'}
# 将集合转换成元组
>>> tuple(def_set)
('k', 'l', 'e')
总结¶
Python 中的集合,因其元素唯一的特性,常用于数据的去重,当然,它也可用于数学集合的相关计算。
定义集合可使用
set()方法,但不能使用{},因为大括号定义的是一个空字典。集合的内置方法中,部分有操作符与之对应,使用时可自行选择。
集合的内置方法中,有几组方法的效果需要做一下区分。
difference 与 difference_update,求差集
intersection 与 intersection_update,求交集
symmetric_difference 与 symmetric_difference_update,求对称差集
以上几组方法的区别均在于,后者会直接操作原始集合
文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,也可分享集合相关的知识。
原创文章已全部更新至 Github:https://github.com/kelepython/kelepython
为了便于沟通交流,我已创建微信学习交流群,欢迎在后台回复
加群加入我们。
1.8 数字(Number) | 最贴近生活的 Python 数据类型¶
前言¶
Hi,大家好,我是可乐,无论是工作、学习还是生活中,我们都在无时无刻与数字打交道,暂且称之为最贴近生活的
Python 数据类型。
今天,给大家详细介绍一下 Python 中数字的相关知识,并附上相应的案例代码,便于吸收、理解。

数字简介¶
数字 (Number) 是 Python
中基本的数据类型之一,数字类型属于数值型数据,用于存储数值,是不可改变的,数值发生改变时,会重新分配内存空间,产生新的对象。
数字类型提供 标量存储 与 直接访问 ,它包括 整数类型(Int)、
浮点类型(Float)、布尔(Bool)类型、以及
复数(Complex)类型。
整型(Int) :通常被称为是整型或整数,是正或负整数,不带小数点。
浮点型(Float) :浮点型由整数部分与小数部分组成,浮点型也可以使用科学计数法表示(1.8e2 = 1.8 x 10^2 = 180)
复数( (Complex)) :复数由实数部分和虚数部分构成,可以用 a + bj,或者complex(a, b) 表示, 复数的实部 a 和虚部 b 都是浮点型。
布尔(Bool) 型 :数字中的 1 和 0 ,对应布尔型中的真 (True) 和假(Flase)。
数字的相关操作包括数字运算、类型转换、数学函数、以及随机数相关函数等。
初识数字¶
1、定义整型数字对象。
>>> def_int = 18
>>> def_int
18
>>> type(def_int)
<class 'int'>
2、定义浮点型数字对象。
>>> def_float = 1.68
>>> def_float
1.68
>>> type(def_float)
<class 'float'>
3、定义复数型数字对象。
>>> def_complex = 6 + 8j
>>> def_complex
(6+8j)
>>> type(def_complex)
<class 'complex'>
4、使用 del 语句删除数字对象。
>>> def_int = 18
del def_int
>>> def_int
Traceback (most recent call last):
File "<input>", line 1, in <module>
NameError: name 'def_int' is not defined
5、数学常量 e 与 pi
# Python 在 math 模块中定义了常量
# 导入对应的常量
>>> from math import e, pi
# 自然对数
>>> e
2.718281828459045
# 圆周率
>>> pi
3.141592653589793
6、与布尔值对应的数字。
# 将 Bool 值与数字做等值判断
>>> True == 1
True
>>> False == 0
True
数字基本操作符¶
数字基本操作符可参照下表:
操作符 |
说明 |
|---|---|
a + b |
a 与 b 的和 |
a - b |
a 与 b 的差 |
a / b |
a 与 b 的商 |
a // b |
a 与 b 商的整数部分 |
% |
a 与 b 的取余运算,也称模运算 |
- a |
a 的负数 |
+= |
自加运算 |
-= |
自减运算 |
*= |
自乘运算 |
/= |
自除运算 |
a ** b |
a 的 b 次幂 |
1、和与差运算。
>>> 2 + 6
8
>>> 6 - 2
4
# 整型与浮点型运算的结果是浮点型
>>> 6 + 1.68
7.68
>>> 6 - 1.68
4.32
2、积与商运算。
>>> 2 * 6
12
# 整除的结果也为浮点型
>>> 6 / 2
3.0
>>> 1.5 * 2
3.0
>>> 6 / 1.5
4.0
3、取商得整数部分。
# 运算中包含浮点型,结果就为浮点型
>>> 6 // 2
3
>>> 6.0 // 2
3.0
# 不可整除的运算仅取整数部分
# 并不会对小数部分四舍五入
>>> 6 // 4
1
>>> 14 // 3
4
4、取余运算(模运算)。
# 整除时余数为 0
>>> 15 % 5
0
>>> 8 % 3
2
>>> 14 % 5
4
# 运算中包含浮点型,结果就为浮点型
>>> 8.0 % 3
2.0
5、自加运算。
>>> def_int = 18
# 此语句等价于:
# def_int = def_int + 1
>>> def_int += 1
>>> def_int
19
6、自减运算。
>>> def_int = 18
# 此语句等价于:
# def_int = def_int - 1
>>> def_int -= 1
>>> def_int
17
7、自乘运算。
>>> def_int = 8
# 此语句等价于:
# def_int = def_int * 2
>>> def_int *= 2
>>> def_int
16
8、自除运算。
>>> def_int = 8
# 此语句等价于:
# def_int = def_int / 2
>>> def_int /= 2
>>> def_int
4.0
9、幂运算。
# 2 的 3 次方,等价于:
# 2 * 2 * 2
>>> 2 ** 3
8
>>> 3 ** 3
27
数字类型转换方法¶
数字类型转换相关方法可参照下表:
方法 |
说明 |
|---|---|
int(obj) |
将对象转换为整型 |
float(obj) |
将对象转换为浮点型 |
complex(obj) |
将对象转换为复数型,虚部为 0 |
complex(a, b) |
生成一个复数,a 为实部,b 为虚部 |
1、使用 int 方法,将对象转换为整型。
>>> int(8.0)
8
>>> int(5.2)
5
# int 方法不会进行四舍五入操作
>>> int(5.8)
5
2、使用 float 方法,将对象转换为浮点型。
>>> float(8)
8.0
>>> float(88)
88.0
3、使用 complex 方法,将对象转换为复数型。
# 不指定虚部,默认为 0
>>> complex(8)
(8+0j)
# 指定虚部
>>> complex(8, 6)
(8+6j)
数字运算内置函数¶
Python 中的提供了一系列的数字运算内置函数,相关用法可参照下表:
函数 |
说明 |
|---|---|
max(x1,x2,...) |
求给定序列的最大值 |
min(x1,x2,...) |
求给定序列的最小值 |
abs(obj) |
求绝对值 |
fabs(obj) |
math 模块提供,求绝对值 |
ceil(obj) |
math 模块提供,上入取整数 |
floor(obj) |
math 模块提供,下舍取整数 |
exp(x) |
math 模块提供,求 e 的 x 次幂 |
pow(x, y) |
幂运算,与 x ** y 类似 |
round(x [,n]) |
四舍五入 |
sqrt(x) |
math 模块提供,求平方根 |
modf(x) |
math 模块提供,返回整数、小数部分 |
log(x) |
math 模块提供,求以 e 为底数的 x 对数 |
log10(x) |
math 模块提供,求以10 为底数的 x 对数 |
下面通过案例逐一演示。
1、使用 max、min 函数,求最大值、最小值 。
>>> max(1, 6, 2.5)
6
>>> min(1, 6, 2.5)
1
2、使用 abs、fabs 函数,求绝对值。
# abs 函数
>>> abs(10)
10
>>> abs(-10)
10
# math 中的 fabs 函数
>>> from math import fabs
# 返回结果为浮点型
>>> fabs(-10)
10.0
3、使用 ceil、floor 函数,对数字取整。
>>> from math import ceil, floor
# ceil 上入取整
>>> ceil(5.2)
6
# floor 下舍取整
>>> floor(5.8)
5
4、使用 exp函数,对常量 e 进行幂运算。
>>> from math import exp, e
# 先看下数学中的常量 e
>>> e
2.718281828459045
# e 的平方
>>> exp(2)
7.38905609893065
5、使用 pow 函数,进行幂运算。
# 2 的平方
>>> pow(2, 2)
4
# 3 的平方
>>> pow(3, 2)
9
6、使用 round 函数,对数字进行四舍五入操作。
>>> round(5.2)
5
>>> round(5.8)
6
# 指定小数点后保留的位数
>>> round(5.888, 2)
5.89
7、使用 sqrt 函数,求平方根。
>>> from math import sqrt
# 求 4 的平方根
>>> sqrt(4)
2.0
# 求 9 的平方根
>>> sqrt(9)
3.0
8、使用 modf 函数,返回数字的整数和小数部分。
>>> from math import modf
# 为什么小数部分不是 0.8
# 而是 0.8000000000000007 呢?
# 计算机采用二进制的方式存储数据
# 这里不再深究,有兴趣的朋友可以研究下
>>> modf(10.8)
(0.8000000000000007, 10.0)
>>> modf(16.8)
(0.8000000000000007, 16.0)
9、使用 log 、log10 函数,求对数。
>>> from math import log, log10
# log 以 e 为底数求对数
>>> log(10)
2.302585092994046
>>> log(100)
4.605170185988092
# log10 以 10 为底数求对数
>>> log10(10)
1.0
>>> log10(100)
2.0
随机数相关方法¶
工作中的一些应用场景,会经常使用到随机数,Python 中的 random
模块封装了随机数的相关操作方法,相关用法可参照下表:
函数 |
说明 |
|---|---|
random() |
在 [0,1) 范围内随机生成一个实数 |
uniform(x, y) |
在 [x,y] 范围内随机生成一个实数 |
randint(x, y) |
在 [x,y] 范围内随机生成一个整数 |
choice(seq) |
在序列中随机选择一个元素 |
shuffle(seq) |
对序列的中的元素随机排序 |
randrange ([start,] stop [,step]) |
在[start,stop)范围内按步长获取随机整数,步长默认为 1 |
下面通过案例逐一演示。
1、使用 random 方法,生成 [0,1) 范围内的随机数。
# 导入 random 模块
>>> import random
# 调用 random 方法
>>> random.random()
0.8136318951871051
>>> random.random()
0.3454891745061127
2、使用 uniform 方法,在指定范围内生成一个随机数。
>>> import random
# 在 [0, 10] 范围内生成随机数
>>> random.uniform(1, 10)
9.71818269408875
>>> random.uniform(1, 10)
6.691348571331768
3、使用 randint 方法,在指定范围内生成一个随机整数。
>>> import random
# 在 [0, 10] 范围内生成随机整数
>>> random.randint(1, 10)
2
>>> random.randint(1, 10)
10
4、使用 choice 方法,在序列中随机选择一个元素。
>>> import random
# 在序列中随机选择一个元素
>>> random.choice([1, 3, 5, 7, 8])
3
>>> random.choice([1, 3, 5, 7, 8])
7
5、使用 shuffle 方法,对序列的中的元素随机排序。
>>> import random
>>> def_seq = [1, 3, 5, 7, 8]
>>> random.shuffle(def_seq)
>>> def_seq
[3, 8, 5, 1, 7]
>>> random.shuffle(def_seq)
>>> def_seq
[1, 7, 5, 8, 3]
6、使用 randrange 方法,在指定范围按特定步长获取随机整数。
>>> import random
# 不指定步长,默认为 1
>>> random.randrange(1, 10)
7
>>> random.randrange(1, 10)
6
# 指定步长,只取奇数
>>> random.randrange(1, 10, 2)
9
>>> random.randrange(1, 10, 2)
7
扩展 - 时间格式转换¶
使用 divmod 方法将时间秒数转换为 时:分:秒 的格式
# 定义一个函数
>>> def seconds_to_hms(seconds):
"""
秒转换为时分秒的形式
:return:转换转换后的格式
"""
seconds = int(seconds)
m, s = divmod(seconds, 60)
h, m = divmod(m, 60)
h_m_s = "%02d:%02d:%02d" % (h, m, s)
return h_m_s
# 调用函数
>>> seconds_to_hms(100)
'00:01:40'
>>> seconds_to_hms(3600)
'01:00:00'
扩展 - 猜数字游戏
import random
# 定义一个函数
>>> def guess_number():
"""
猜数字游戏
:return:相关提示语
"""
random_num = random.randint(1, 10)
while True:
# 引导玩家输入 10 以内的整数
input_number = int(input("请输入10以内的整数:"))
if input_number > random_num:
print("大啦,继续加油")
elif input_number < random_num:
print("小啦,继续加油")
else:
print("恭喜你猜中拉")
break
>>> guess_number()
请输入10以内的整数: 10
大啦,继续加油
请输入10以内的整数: 5
小啦,继续加油
请输入10以内的整数: 6
恭喜你猜中拉
总结¶
Python 中数字相关的操作比较丰富 ,
三角函数相关的操作我在工作中很少使用,有兴趣的朋友可以自行尝试。数字的基本操作符应用比较广泛,在遇到相关需求时,选择合适的使用即可,当然有时也需要配合、嵌套使用。
内置函数中求最值、取整、幂运算等相对较常用,随机数相关的函数也十分重要,如在设计短信、图片验证码时常会用到。
文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,也可分享数字相关的操作技巧、有趣的小案例。
原创文章已全部更新至 Github:https://github.com/kelepython/kelepython
本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c01/c01_08.html
1.9 如果(If) | Python 中的条件控制语句详解¶
前言¶
Hi,大家好,我是可乐,生活中曾听到过太多的如果,如果当年我再认真一点,如果我高考的物理多选题没有多选选项,如果我大学时多学些技能,如果我早点买房等等。
工作中,同样存在很多 如果 ,今天给大家详细介绍 Python
中的条件控制语句,并附上相应的案例代码,便于吸收、理解。
条件控制语句简介¶
Python 中的 条件控制语句 (Conditional control statement)
是通过一条或者多条语句的执行结果(True 或者
False),来决定执行的代码逻辑 。
它包含 if 、elif 、else 关键字, Python 中没有
else if 的写法,只存在 elif 这种写法。
每句判断语句使用冒号 - : 结尾,使用 缩进
划分语句块,相同缩进数的语句组成一个语句块。
条件控制语句,包括 if 语句、if - else 语句、if - elif - else 语句、以及 if - elif (多个elif) - else 语句,下面我们通过案例逐一演示。
if 语句¶
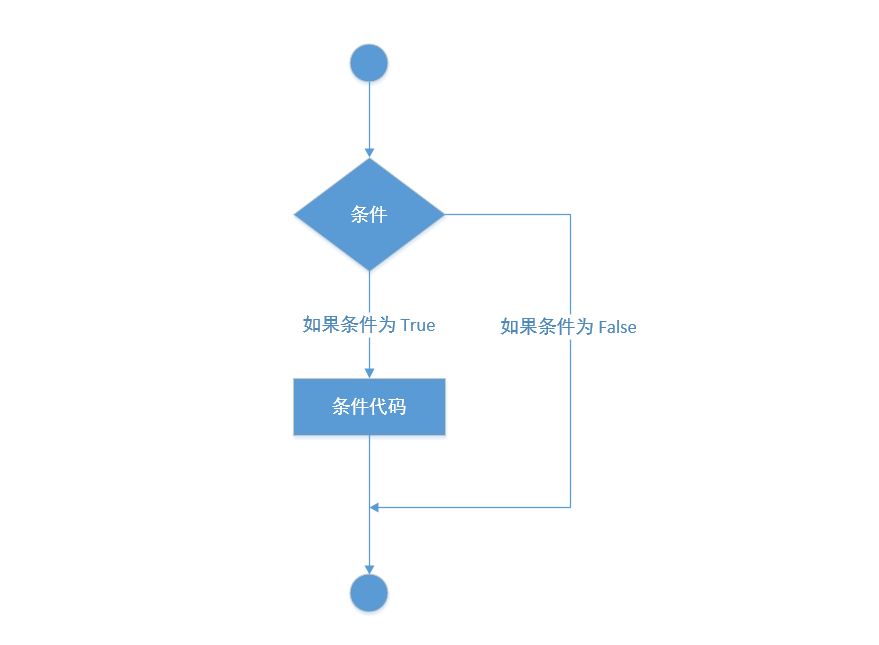
if 语句,仅有一个判断条件,如果条件成立(为 True),则执行判断语句后带缩进的代码逻辑,否则不执行。
1、语法格式:
# 语句末尾的冒号一定不能丢
if 判断条件:
# 注意与 if 缩进
条件为真才执行的代码逻辑
2、执行流程图:
3、案例:
>>> if True:
print("条件为真时打印的语句")
条件为真时打印的语句
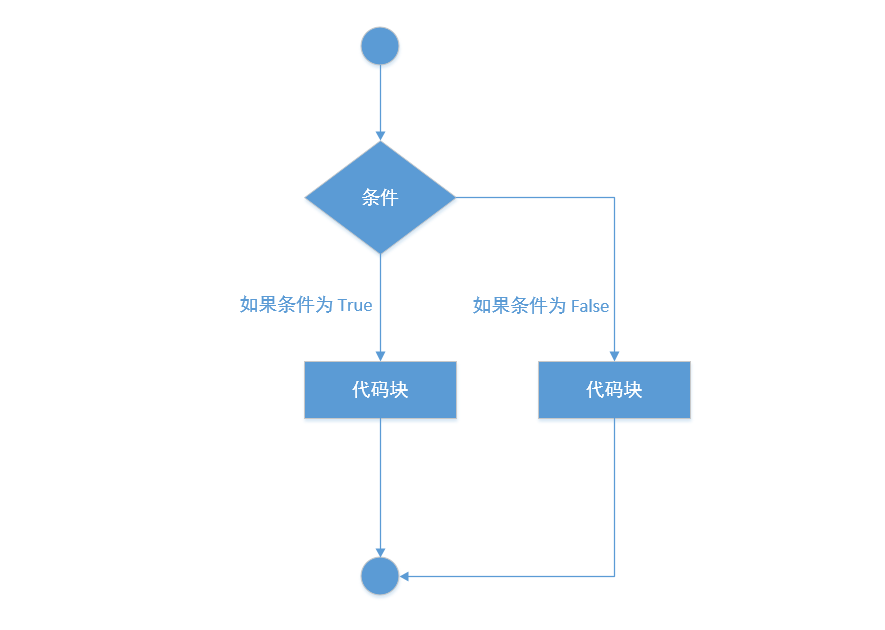
if - else 语句¶
if - else 语句,仅有一个判断条件,与 if 语句的区别在于,如果条件成立(为 True),则执行 if 判断语句后带缩进的代码逻辑,否则执行 else 后带缩进的代码逻辑。
1、语法格式:
# 语句末尾的冒号一定不能丢
if 判断条件:
# 注意与 if 缩进
条件为真时执行的代码逻辑
else:
# 注意与 else 缩进
条件为假时执行的代码逻辑
2、执行流程图:
3、案例:
>>> if True:
print("条件为真时打印的语句")
else:
print("条件为假时打印的语句")
条件为真时打印的语句
>>> if False:
print("条件为真时打印的语句")
else:
print("条件为假时打印的语句")
条件为假时打印的语句
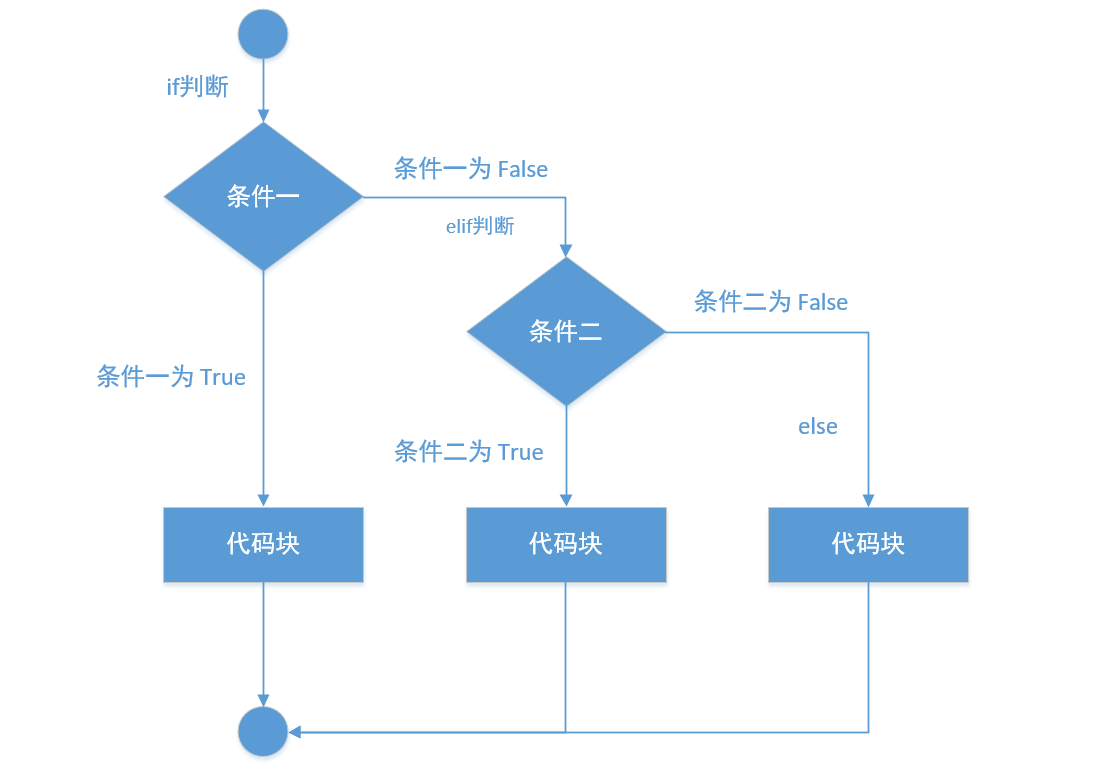
if - elif - else 语句¶
在使用判断语句时,我们有时需要对两个条件进行判断,并执行对应的代码逻辑,这时以上两种语句就无法满足我们的需求。
我们可使用 if - elif - else 语句,有两个判断条件,如果 if 后的条件成立(为 True),则执行 if 判断语句后带缩进的代码逻辑,如果 elif 后的条件成功(为 True),则执行 elif 判断语句后带缩进的代码逻辑,否则执行 else 后带缩进的代码逻辑。
值得注意的是,if - elif - else 语句中,仅有一个条件成立后,就会退出当前整个判断语句,简单来说,这三条判断路径,只会走其中一条。
1、语法格式:
# 语句末尾的冒号一定不能丢
if 判断条件一:
# 注意与 if 缩进
条件一为真时执行的代码逻辑
elif 判断条件二:
# 注意与 if 缩进
条件二为真时执行的代码逻辑
else:
# 注意与 else 缩进
条件一、条件二都为假时执行的代码逻辑
2、执行流程图:
3、案例:
>>> drink = "kele"
>>> if drink == "kele":
print("你选择的饮品是可乐")
elif drink == "xuebi":
print("你选择的饮品是雪碧")
else:
print("你选择的既不是可乐,也不是雪碧")
你选择的饮品是可乐
if - elif (多个) - else 语句¶
与 if - elif - else 语句的区别在于,elif 条件判断的数量不止一个。
1、语法格式:
# 语句末尾的冒号一定不能丢
if 判断条件一:
# 注意与 if 缩进
条件一为真时执行的代码逻辑
elif 判断条件二:
# 注意与 if 缩进
条件二为真时执行的代码逻辑
...
elif 判断条件N:
# 注意与 if 缩进
条件N为真时执行的代码逻辑
else:
# 注意与 else 缩进
条件一、条件二、...条件N都为假时执行的代码逻辑
2、执行流程图:
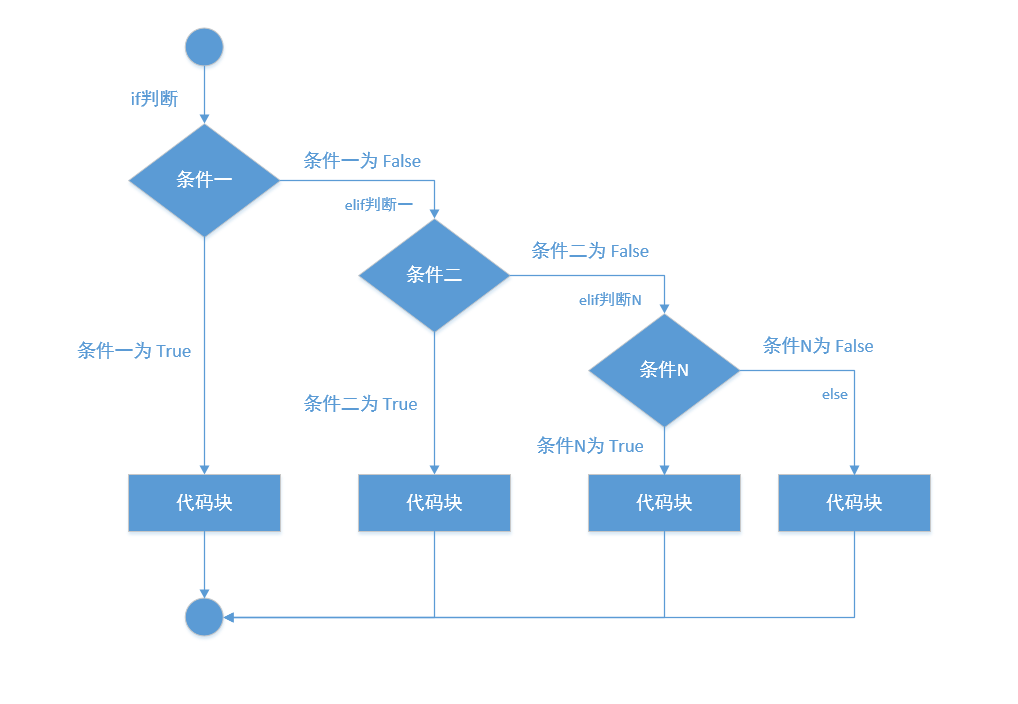
3、案例:
>>> drink = "xo"
>>> if drink == "kele":
print("你选择的饮品是可乐")
elif drink == "xuebi":
print("你选择的饮品是雪碧")
elif drink == "tea":
print("你选择的饮品是茶")
else:
print("你选择的不是可乐,不是雪碧,也不是茶")
你选择的不是可乐,不是雪碧,也不是茶
嵌套使用¶
以上四种条件控制语句,均支持自身嵌套、以及彼此嵌套使用,下面以 if 语句 与 if- else 语句为例:
if 语句自身嵌套使用¶
>>> drink = "kele"
>>> ice = "True"
# 第一层判断是否是可乐
>>> if drink == "kele":
# 第二层判断是否加冰
if ice == "True":
print("你选择的饮品是可乐加冰")
你选择的饮品是可乐加冰
if - else 语句自身嵌套使用¶
>>> drink = "kele"
>>> ice = "True"
>>> if drink == "kele":
if ice == "True":
print("你选择的饮品是可乐加冰")
else:
print("你选择的饮品是可乐不加冰")
else:
print("你选择的饮品不是可乐")
你选择的饮品是可乐加冰
if 语句与 if - else 语句彼此嵌套使用¶
>>> drink = "kele"
>>> ice = "False"
>>> if drink == "kele":
if ice == "True":
print("你选择的饮品是可乐加冰")
else:
print("你选择的饮品是可乐不加冰")
你选择的饮品是可乐不加冰
条件控制语句中常用的基础运算符¶
常用的基础运算符可参照下表:
操作符 |
说明 |
|---|---|
< |
小于 |
<= |
小于或者等于 |
> |
大于 |
>= |
大于或者等于 |
== |
等于,比较两侧对象的值是否相等 |
!= |
不等于 |
in / not in |
成员运算符 |
is / not is |
身份运算符 |
1、小于 - < 与 小于或者等于 - <=
>>> score = 59
>>> if 0 < score < 60:
print("未及格,继续努力")
elif 60 <= age < 69:
print("及格,继续进阶")
else:
print("中等、良好、或优秀")
未及格,继续努力
2、大于 - > 与 大于或者等于 - >=
>>> score = 91
>>> if score >= 60:
print("及格,继续进阶")
elif score > 90:
print("优秀")
else:
print("其他等级")
优秀
3、等于 - == 与 不等于 - !=
>>> password = "123456"
>>> if password == "123456":
print("登陆成功")
登陆成功
>>> user_name = "zhangsan"
>>> if user_name != "root":
print("没有操作权限")
没有操作权限
4、成员运算符 in 、not in 判断成员是否在序列中
>>> user_list = ["kele","zhangsan"]
>>> login_name = "lisi"
>>> if login_name not in user_list:
print("用户不存在")
elif login_name in user_list:
print("登陆成功")
用户不存在
5、身份运算符 is 、not is 比较两个对象的存储单元
>>> kele_age = 18
>>> xuebi_age = 18
>>> if kele_age is xuebi_age:
print("两者指向同一块内存空间")
if kele_age not is xuebi_age:
print("两者指向不同的内存空间")
两者指向同一块内存空间
条件控制语句中常用的逻辑运算符¶
常用的逻辑运算符可参照下表:
运算符 |
说明 |
|---|---|
not |
逻辑非 |
and |
逻辑与 |
or |
逻辑或 |
1、逻辑非 - not,对语句的布尔值取反
>>> bool_1 = True
>>> bool_2 = False
>>> if not bool_1:
print("对真取非为假")
if not bool_2:
print("对假取非为真")
对假取非为真
2、逻辑与 - and,找 False,若第一个语句的值为 False 则直接返回
False,否则,返回第二个语句的值
# 有假则为假
>>> bool_1 = True
>>> bool_2 = False
>>> bool_3 = True
>>> if bool_1 and bool_2:
print("有假则为假")
if bool_1 and bool_3:
print("全真才为真")
全真才为真
3、逻辑或 - or,找 True,若第一个语句的值为 True 则直接返回
True,否则,返回第二个语句的值
# 有真则为真
>>> bool_1 = True
>>> bool_2 = False
>>> bool_3 = False
>>> if bool_1 or bool_2:
print("有真则为真")
if bool_2 or bool_3:
print("全假才为假")
有真则为真
扩展 - Python 中的特殊对象¶
Python 中有部分特殊对象,它们的布尔值为 False,具体可参照下表:
对象 |
布尔值 |
|---|---|
None |
False |
所有值为零的数(整数、复数、浮点数) |
False |
空字符串 |
False |
空列表 |
False |
空元组 |
False |
空字典 |
False |
空集合 |
False |
下面我们逐一验证
1、None 与值为零的数
>>> if not None:
print("None 的布尔值为 False")
None 的布尔值为 False
>>> if not 0:
print("0 的布尔值为 False")
0 的布尔值为 False
>>> if not 0.0:
print("0.0 的布尔值为 False")
0.0 的布尔值为 False
>>> if not 0 + 0j:
print("0 + 0j 的布尔值为 False")
0 + 0j 的布尔值为 False
2、空字符串、空列表、空元组
>>> if not "":
print("空字符串的布尔值为 False")
空字符串的布尔值为 False
>>> if not []:
print("空列表的布尔值为 False")
空列表的布尔值为 False
>>> if not tuple():
print("空元组的布尔值为 False")
空元组的布尔值为 False
3、空字典、空集合
>>> if not {}:
print("空字典的布尔值为 False")
空字典的布尔值为 False
>>> if not set():
print("空集合的布尔值为 False")
空集合的布尔值为 False
扩展 - 使用否定判断精简代码¶
工作中,多使用否定判断,可精简部分代码,下面通过一个简单的案例说明
# 传统写法
is_kele = True
if is_kele:
print("Yes")
else:
print("No")
# 否定判断
is_kele = True
if not is_kele:
print("No")
print("Yes")
扩展 - 猜拳游戏¶
import random
def guessing_game():
"""
猜拳游戏 if - elif - else 与 逻辑运算符
Author:可乐python说
:return:
"""
player_input = int(input("请出拳(0剪刀,1石头,2布):"))
computer_ = random.randint(0, 2)
if (player_input == 0 and computer_ == 2) \
or (player_input == 1 and computer_ == 0) \
or (player_input == 2 and computer_ == 0):
print("电脑出拳%s,恭喜你赢了!" % computer_)
elif (player_input == 0 and computer_ == 0) \
or (player_input == 1 and computer_ == 1) \
or (player_input == 2 and computer_ == 2):
print("电脑出拳%s,平局!" % computer_)
else:
print("电脑出拳%s,很遗憾你输了!" % computer_)
if __name__ == '__main__':
guessing_game()
扩展 - 火车检票进站¶
def train_check_in():
"""
火车检票入站 if - else 嵌套
Author:可乐python说
:return:
"""
train_ticket = int(input("请出示车票(1表示有,0表示无):"))
is_safe = int(input("请过安检(1表示安全,0表示危险):"))
if train_ticket == 1:
if is_safe == 1:
print("通过安检,可以上车!")
else:
print("你携带了违规物品,没通过安检,不能上车!")
else:
print("没有车票,不能进站!")
if __name__ == '__main__':
train_check_in()
总结¶
工作中在处理业务逻辑时,经常会使用到条件控制语句,当然,以嵌套使用为主。
使用条件控制语句时,可根据实际需求,灵活搭配使用基本运算符与逻辑运算符。
书写时需注意条件控制语句后的冒号 -
:,以及代码块的缩进问题。if - else 语句可理解为二选其一,if - elif - else 则为三选其一,包含多个 elif 则为 N 选其一,其中 else 并非必须选项。
使用逻辑运算符时,其优先级需要注意,加上小括号 -
()的语句优先级最高,() > not > and > or 。使用条件控制语句时,建议多使用否定判断,这时值为空的特殊对象常被使用,可在一定程度上精简代码。
文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,也可分享条件判断语句相关的技巧、有趣的小案例。
原创文章已全部更新至 Github:https://github.com/kelepython/kelepython
本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c01/c01_09.html
1.10 基础 | Python 循环语句详解¶

循环语句简介¶
循环语句 (Loop statement)
又称重复结构,用于反复执行某一操作,面对大数量级的重复运算,即使借助计算机,也会比较耗时。
循环语句一般都与 条件控制语句
搭配使用,根据循环判断条件的返回值,决定是否执行循环体,条件控制语句的相关内容请阅读文章。
循环有两种模式,一种是条件满足时执行循环体,称为 当型循环
;一种是在条件不满足时执行循环体,称为 直到型循环 。
Python 中的循环语句包括 while 循环 与 for 循环
,前者凭借循环判断条件指定循环范围,后者采用遍历的形式指定循环范围。
为了更加灵活的控制循环语句,Python 中还提供了 break 、continue
以及 pass 等语句,下面我们通过案例逐一演示。
while 循环语句¶
while 循环语句,与条件控制语句搭配使用,当满足一定条件时,重复执行对应的循环体代码逻辑,否则跳出循环。
1、语法格式:
# 注意句末的冒号
while 循环判断条件:
# 注意循环体缩进
循环体
2、执行流程图:
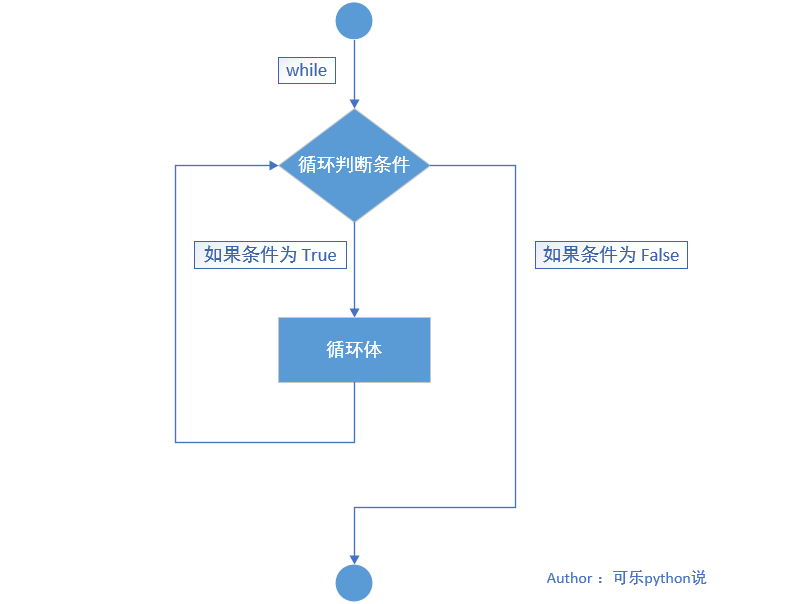
3、案例(重复打印 5 次):
>>> init_num = 0
while init_num < 5:
print("Hi,我是可乐")
init_num += 1
Hi,我是可乐
Hi,我是可乐
Hi,我是可乐
Hi,我是可乐
Hi,我是可乐
while - else 循环语句¶
与 while 循环语句类似,区别在于,while - else 循环语句在条件不满足退出循环时,会先执行 else 后面带缩进的代码逻辑。
1、语法格式:
while 循环判断条件:
循环体
else:
代码逻辑
2、执行流程图:
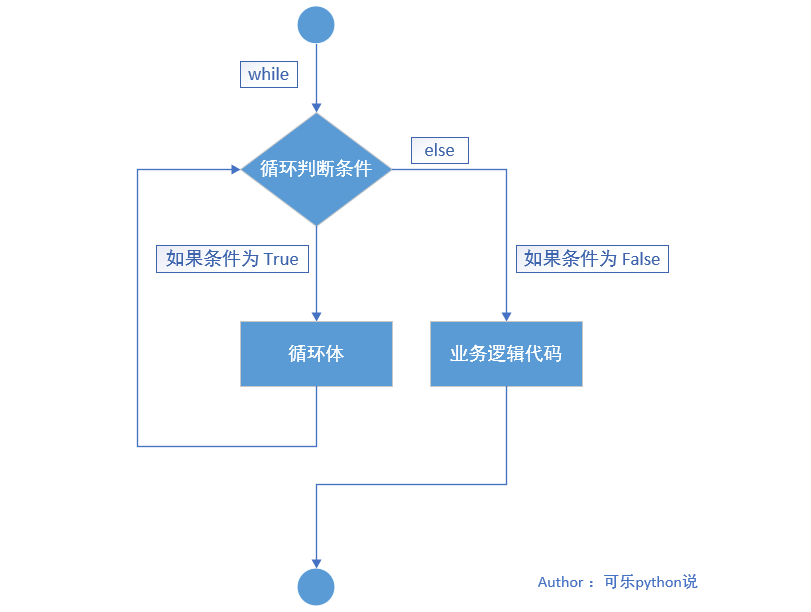
3、案例:
>>> init_num = 0
while init_num < 5:
print("{} 小于 5".format(init_num))
init_num += 1
else:
# 推出循环时执行的代码逻辑
print("可乐python说")
0 小于 5
1 小于 5
2 小于 5
3 小于 5
4 小于 5
可乐python说
for 循环语句¶
Python 中的 for 循环是迭代循环,可以遍历任何的序列对象或可迭代对象,如 str、list、tuple 、 dict 等。
遍历时,for 循环语句将遍历对象中的所有成员,遍历顺序与成员在对象中的顺序一致,它会对每个成员执行一次循环体,循环的次数在程序开始运行时就已经指定。
for 循环语句由 for 与 in 搭配组成,它依次迭代出对象中的每个元素,并将元素的值传递给临时变量,然后执行一次循环体。
1、语法格式:
# 注意句末的冒号
for 变量 in 可迭代对象(序列):
# 注意循环体缩进
循环体
2、执行流程图:
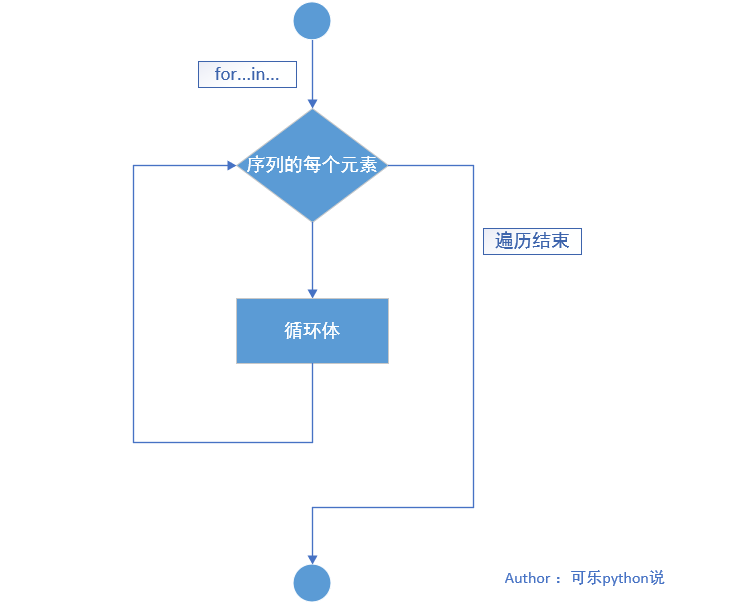
3、案例:
>>> for i in "Python":
print(i)
P
y
t
h
o
n
for - else 循环语句¶
与 for 循环语句一样,增加 else 语句,在完成指定遍历次数后,会优先执行 else 后带缩进的代码逻辑。
1、语法格式:
for 变量 in 可迭代对象(序列):
循环体
else:
代码逻辑
2、执行流程图:
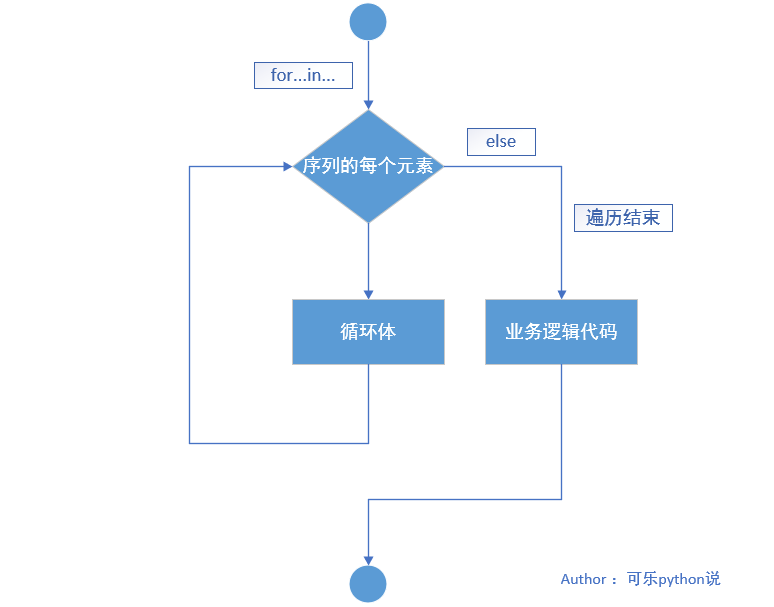
3、案例:
>>> for i in ["kele", "xuebi"]:
print(i)
else:
print("循环结束")
kele
xuebi
循环结束
for 循环中的 range 函数¶
我们在遍历数字序列时,会经常使用到 Python 中内置的
range 函数,它获取的数字序列遵循 左开右闭 原则,下面请看案例。
1、语法格式
for i in range(satrt, stop, step):
业务逻辑
# satrt :开始位置
# stop :结束位置
# step :步长
2、不指定开始位置与步长,默认从 0 开始,步长默认为 1
>>> for i in range(5):
print(i)
0
1
2
3
4
3、指定开始位置与结束位置,并指定从 1 开始取值
>>> for i in range(1, 5):
print(i)
1
2
3
4
4、指定开始、结束位置,以及步长,取 10 以内的偶数
>>> for i in range(0, 10, 2):
print(i)
0
2
4
6
8
循环语句嵌套使用¶
工作中,我们有时也会将循环语句嵌套使用,下面我们演示 while 循环与 for 循环语句的嵌套使用。

while 循环语句嵌套¶
1、语法格式
while 判断条件一:
循环体一
while 判断条件二:
循环体二
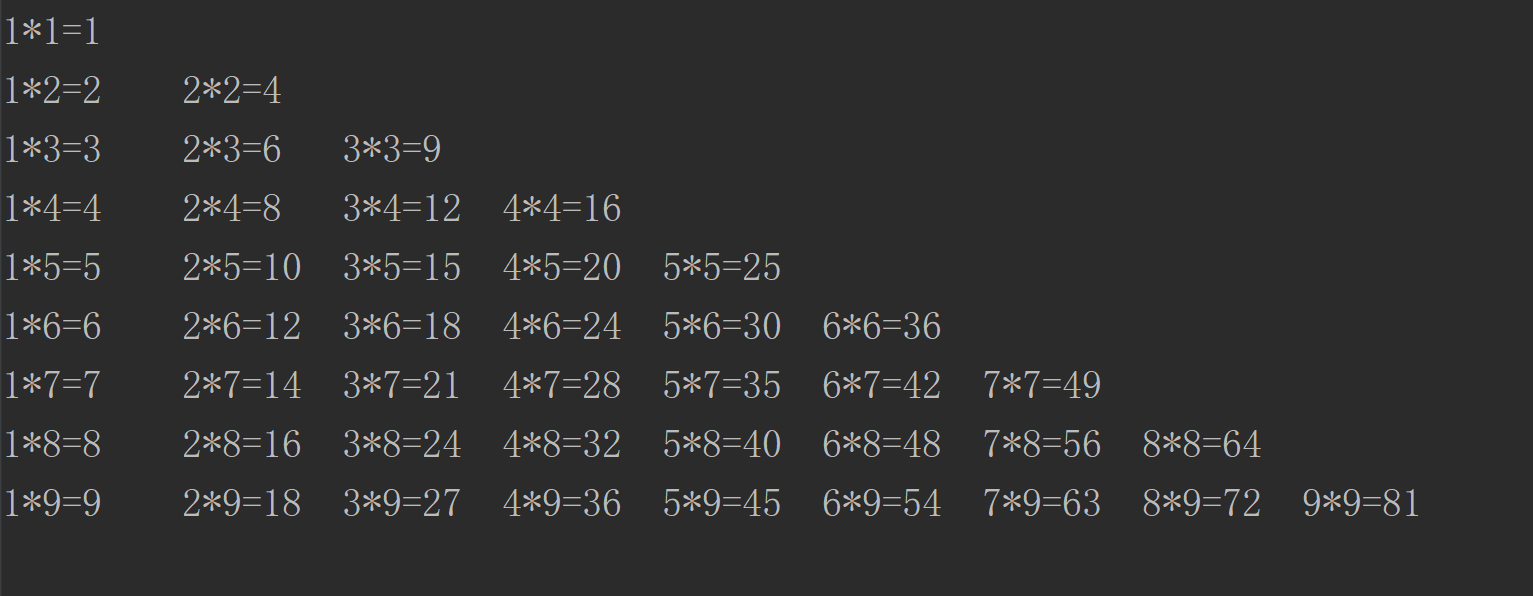
2、案例 - 打印九九乘法表
>>> i = 1
while i <= 9:
j = 1
while j <= i:
print("%d*%d=%d\t" % (j, i, j*i), end=" ")
j += 1
print("")
i += 1
效果如下:
for 循环语句嵌套¶
1、语法格式
for 变量 in 可迭代对象(序列):
循环体一
for 变量 in 可迭代对象(序列):
循环体二
2、案例 - 打印三角形
>>> for i in range(1, 8, 2):
# 不需要显示星号的位置使用空格填充
print(int((7 - i) / 2) * " ", end="")
for j in range(i):
# 分别在每一行打印对应数量的星号
print("*", end="")
print()
*
***
*****
*******
循环语句中的 break 语句¶
break 语句 会终止包含它的循环语句,如果 break
语句在嵌套循环中使用,则它将终止最里面的循环语句。
1、执行流程图
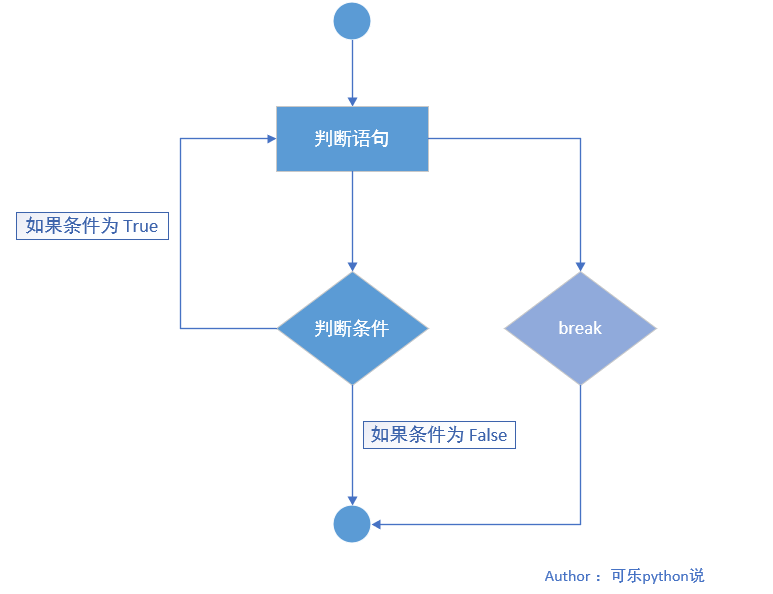
2、案例
>>> for i in range(5):
if i == 2:
break
print(i)
print("结束遍历")
# 当遍历元素等于 2 时直接退出整个循环
0
1
结束遍历
循环语句中的 continue 语句¶
continue 语句
仅用于跳过本次循环,循环并不会终止,会继续执行下一次循环。
1、执行流程图
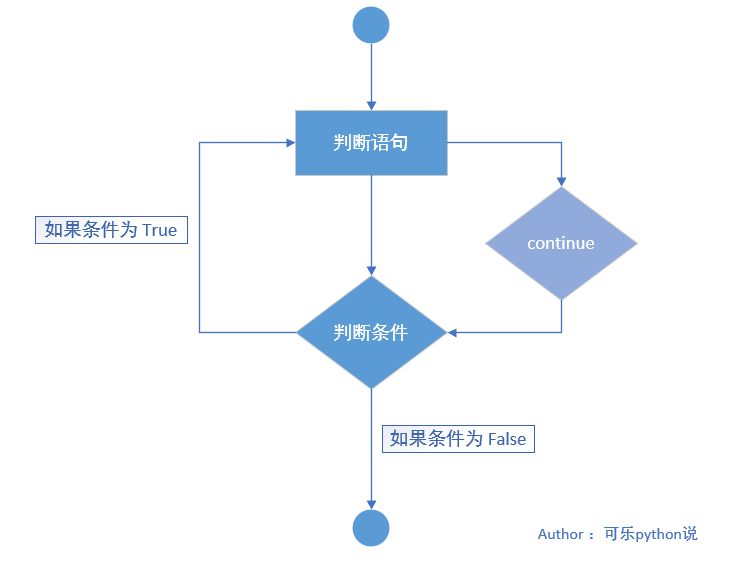
2、案例
>>> for i in range(5):
if i == 2:
continue
print(i)
print("结束遍历")
# 当遍历元素等于 2 时仅退出本次循环
0
1
3
4
结束循环
循环语句中的 pass 语句¶
pass 语句 是 Python
中的空语句,程序执行到此语句直接跳过,不会做任何的操作,仅作占位语句,但它在保持程序结构的完整性方面,有一定价值。
1、语法格式
pass 之前的业务逻辑
pass
pass 之后的业务逻辑
2、案例
>>> for i in range(10):
if i % 2 == 0:
# 不做任何操作
pass
else:
print("{} 不能被 2 整除".format(i))
1 不能被 2 整除
3 不能被 2 整除
5 不能被 2 整除
7 不能被 2 整除
9 不能被 2 整除
扩展 - 无限循环¶
无限循环,也称死循环,是永远都不会结束的循环,我们需要通过设置条件表达式的值永远为
True 来实现无限循环。

1、语法格式
while 永远为 True 的判断条件:
循环体
2、案例
>>> author = "kele"
# 条件永远为 True
while author == "kele":
print("欢迎关注 可乐python说")
欢迎关注 可乐python说
欢迎关注 可乐python说
欢迎关注 可乐python说
欢迎关注 可乐python说
欢迎关注 可乐python说
欢迎关注 可乐python说
欢迎关注 可乐python说
欢迎关注 可乐python说
...
# 循环永远都不会结束
# 可使用 Ctrl + C 结束程序
扩展 - 列表推导式¶
列表推导式(List Comprehension),是 Python 中的一个很棒的
语法糖,也称为列表解析式,它提供了一种简明扼要的方法来创建一个新列表。
前面我们提到的 for 循环嵌套使用,业务代码显得有点冗余,也相对耗性能,下面我们将使用列表推导式来代替它。
1、语法格式
out_list = [表达式 for 变量 in 列表 条件判断语句等]
2、案例 - 生成由 0 ~ 10 所有整数的平方组成的新列表
>>> out_list = [i**2 for i in range(10)]
>>> out_list
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
3、案例 - 生成由 0 ~ 10 所有偶数的平方组成的新列表
>>> out_list = [i**2 for i in range(10) if i % 2 ==0]
>>> out_list
[0, 4, 16, 36, 64]
4、与传统嵌套使用消耗时间对比
# 传统 for 循环嵌套
# 完成 0-1000 每个数两两相乘
>>> # 导入 time 模块用于计时
import time
start_time = time.time()
out_list = []
for i in range(1000):
for j in range(1000):
out_list.append(i*j)
print(len(out_list))
end_time = time.time()
print(end_time-start_time)
# 新列表共一百万个元素
# 耗时约 0.179 秒
1000000
0.17854714393615723
# 传统列表推导式
# 完成 0-1000 每个数两两相乘
>>> import time
start_time = time.time()
out_list = [i*j for i in range(1000) for j in range(1000)]
print(len(out_list))
end_time = time.time()
print(end_time-start_time)
# 新列表共一百万个元素
# 耗时约 0.088 秒,效率提升不少
1000000
0.08780097961425781
扩展 - 计算 1 至 100 整数累加和¶
相信大家对这个案例已经非常熟悉,今天我们使用 Python 中的 for 循环完成这个计算。
>>> num_sum = 0
# 遍历得到 0 至 100 的所有整数
for i in range(101):
# 循环累加求和
num_sum += i
>>> num_sum
5050
总结¶
工作中在处理业务逻辑时,经常会使用到循环语句,其中 for 循环的使用频率高于 while 循环。
使用 while 循环时,一定要注意循环退出的条件,初学者很容易将循环写成无限循环 。
设计循环逻辑时,可灵活结合 break、continue、以及pass 语句,其中 break会直接退出整个循环,而continue仅会退出本次循环,直接进入下次循环,使用时注意区分。
列表推导式的效率远高于 for 循环语句嵌套,它在使用时也十分方便,大家可深入研究,一行代码可带来意想不到的惊喜。
推导式不仅仅适用于列表,还可用于字典、集合等一系列可迭代的数据结构。
文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,也可分享循环语句相关的技巧、以及有趣的小案例。
原创文章已全部更新至 Github :https://github.com/kelepython/kelepython
本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c01/c01_10.html
1.11 Python 中的可迭代对象、迭代器与生成器¶
前言¶
Hi,大家好,我是可乐, 迭代器 与 生成器 是 Python
学习中不可避免的两个有趣的知识点,实际开发中也比较常用。
我们在处理大量数据时,有时会导致计算机内存不足,我们需要将数据分块处理,只处理所需的数据,这将大大减少计算机内存的消耗,这便是迭代器与生成器最直观的作用。

今天,我们一起来探索 迭代器 与 生成器
的相关知识,并附上相关案例代码,便于吸收、理解。
聊到这,我们不得不提起 可迭代对象
这个概念,首先我们用一张图片来展示它们三者之间的关系。
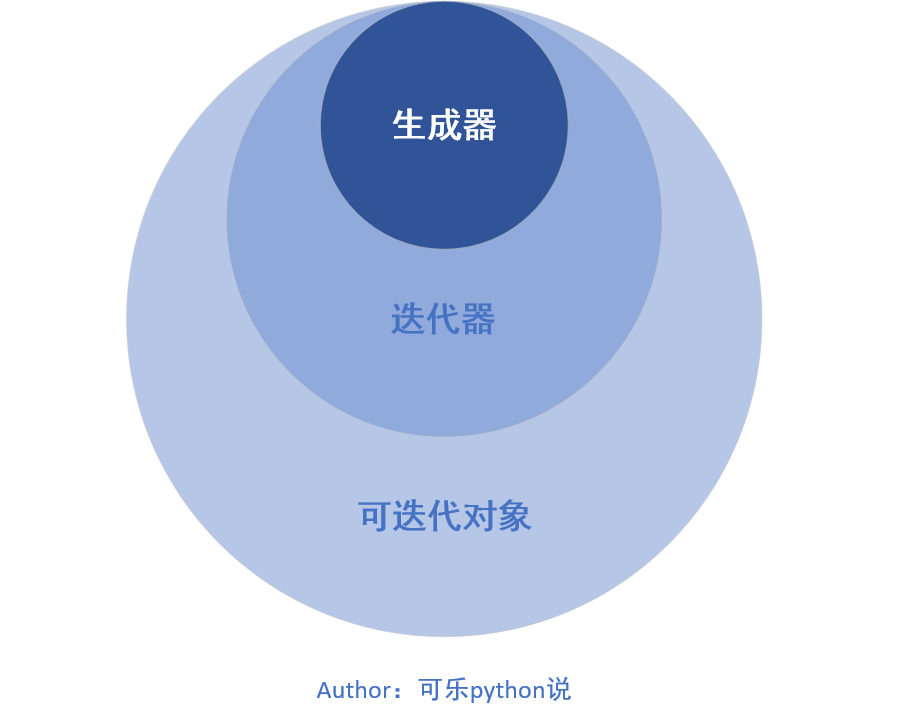
可迭代对象¶
可迭代对象(Iteratable Object)
是能够一次返回其中一个成员的对象,通常使用我们之前介绍过的 for 循环
来完成此操作,如字符串、列表、元组、集合、字典等等之类的对象都属于可迭代对象。
简单来理解,任何你可以循环遍历的对象都是可迭代对象。
1、使用 isinstance()函数 判断对象是否是可迭代对象
# 导入 collections 模块的 Iterable 对比对象
>>> from collections import Iterable
# 字符串是可迭代对象
>>> isinstance("kele", Iterable)
True
# 列表是可迭代对象
>>> isinstance(["kele"], Iterable)
True
# 字典是可迭代对象
>>> isinstance({"name":"kele"}, Iterable)
True
# 集合是可迭代对象
>>> isinstance({1,2}, Iterable)
True
# 数字不是可迭代对象
>>> isinstance(18, Iterable)
False
2、使用 dir()函数 查看对象内所有的属性与方法
# 字符串的所有属性与方法
>>> dir("kele")
[..., '__iter__', '__le__', '__len__', '__lt__', '__mod__', '__mul__', '__ne__', '__new__', '__reduce__', ...]
# 列表的所有属性与方法
>>> dir(["kele"])
[..., '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__',...]
# 字典的所有属性与方法
>>> dir({"name":"kele"})
[..., '__iter__', '__le__', '__len__', '__lt__', '__ne__', '__new__', '__reduce__', ...]
# 数字的所有属性与方法
# 并没有找到 __iter__
>>> dir(18)
['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'numerator', 'real', 'to_bytes']
3、对比可迭代对象与不可迭代对象的所有属性与方法,我们发现:可迭代对象都构建了 ``__iter__`` 方法,而不可迭代对象没有构建,因此我们也可通过此特点来判断某一对象是不是可迭代对象。
4、我们来验证一下这个结论
# 没有定义 __iter__ 方法则是不可迭代对象
>>> from collections import Iterable
>>> class IsIterable:
pass
>>> isinstance(IsIterable(), Iterable)
False
# 定义 __iter__ 方法则是可迭代对象
>>> class IsIterable:
def __iter__(self):
pass
>>> isinstance(IsIterable(), Iterable)
True
5、看到这里,抛出一个思考, __iter__
方法有什么作用,执行它我们能得到什么?
# 调用后,得到了一个与调用对象对应的对象 - iterator
>>> "kele".__iter__()
<str_iterator object at 0x0462CB30>
>>> ["kele"].__iter__()
<list_iterator object at 0x0462CA50>
这里得到的新对象,正是我们接下来要介绍的内容 - 迭代器。
迭代器¶
迭代器(Iterator) 是同时实现__iter__() 与 __next__()
方法的对象。
它可通过 __next__() 方法或者一般的 for
循环进行遍历,能够记录每次遍历的位置,迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束,迭代器只能往前不能后退,终止迭代则会抛出
StopIteration 异常。
1、迭代器是可迭代对象
>>> from collections import Iterable
# 以我们前面得到的迭代器为例
>>> isinstance("kele".__iter__(), Iterable)
True
2、使用 dir()函数 查看迭代器所有的属性与方法
>>> dir("kele".__iter__(), Iterable)
# 我们可以看到迭代器同时实现
# __iter__ 与 __next__ 方法
[..., '__iter__', '__le__', '__length_hint__', '__lt__', '__ne__', '__new__', '__next__', ...]
3、使用 __next__() 方法获取迭代器中的元素
>>> str_iterator = "kele".__iter__()
>>> str_iterator.__next__()
'k'
>>> str_iterator.__next__()
'e'
>>> str_iterator.__next__()
'l'
>>> str_iterator.__next__()
'e'
>>> str_iterator.__next__()
# 终止迭代则会抛出 StopIteration 异常
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
4、使用 next() 与 iter() 方法来实现相同的效果
# 使用 iter() 方法获取一个迭代器
>>> str_iterator = iter("kele")
# 使用 next() 方法获取迭代器中的元素
>>> next(str_iterator)
'k'
>>> next(str_iterator)
'e'
>>> next(str_iterator)
'l'
>>> next(str_iterator)
'e'
>>> next(str_iterator)
# 终止迭代则会抛出 StopIteration 异常
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
5、自己动手实现一个迭代器类,返回偶数
>>> class MyIterator:
"""
迭代器类
Author:可乐python说
"""
# 类构造函数,调用时最先执行
# 用于分配执行最初所需的任何值
def __init__(self):
self.num = 0
# iter()和next()方法使这个类变成迭代器
def __iter__(self):
# 类本身就是迭代器,故直接返回本身
return self
def __next__(self):
# 返回当前值
return_num = self.num
# 并改变下一次调用的状态
self.num += 2
return return_num
>>> my_iterator = MyIterator()
>>> next(my_iterator)
0
>>> next(my_iterator)
2
>>> next(my_iterator)
4
# 思考:for 循环为什么能够自动结束遍历?
6、前文实现的迭代器类,并没有写结束的条件,这里优化一下
>>> class MyIterator:
"""
迭代器类
Author:可乐python说
"""
def __init__(self):
self.num = 0
def __iter__(self):
return self
def __next__(self):
return_num = self.num
# 只要值大于等于6,就停止迭代
if return_num >= 6:
raise StopIteration
self.num += 2
return return_num
>>> my_iterator = MyIterator()
>>> next(my_iterator)
0
>>> next(my_iterator)
2
>>> next(my_iterator)
4
>>> next(my_iterator)
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
7、我们还可对异常进行处理,获取到 StopIteration 异常便退出循环
>>> class MyIterator:
# 以上略...
def __next__(self):
return_num = self.num
# 只要值大于等于6,就停止迭代
if return_num >= 6:
raise StopIteration
self.num += 2
return return_num
>>> my_iterator = MyIterator()
>>> while True:
try:
my_num = next(my_iterator)
except StopIteration:
break
print(my_num)
0
2
4
我们对迭代器捕获异常后,其实就是实现了与 for 循环类似的效果,这也正是 for 循环底层实现的方式,当迭代一个可迭代对象时,for 循环通过 iter() 方法获取要迭代的项,并使用 next() 方法返回后续的项。
迭代器可通过两种方式获取:一种是调用迭代器类中的方法直接返回迭代器,另一种是可迭代对象通过执行
__ iter()__
方法获取,迭代器在一定程度上节省了内存,需要时才去获取对应的数据。
在某些情况下,我们不想遵循迭代器协议,即不想实现__iter__() 与 __next__()
方法
,但我们又想实现与迭代器相同的功能,这时,就需要使用到一种特殊的迭代器,这正是我们接下来要介绍的内容
- 生成器。
生成器¶
Python 中,提供了两种 生成器(Generator)
,一种是生成器函数,另一种是生成器表达式。
生成器函数,定义与常规函数相同,区别在于,它使用 yield 语句
而不是 return 语句 返回结果, yield
语句一次返回一个结果,在每个结果中间,会暂停并保存当前所有的运行信息,以便下一次执行
next() 方法时从当前位置继续运行。
生成器表达式,与列表推导式类似,区别在于,它使用小括号 - ()
包裹,而不是中括号,生成器返回按需产生结果的一个对象,而不是一次构建完整的列表。
1、动手实现一个生成器函数
>>> def my_generator():
my_num = 0
while my_num < 5:
yield my_num
my_num += 1
>>> generator_ = my_generator()
# 得到一个生成器对象
>>> type(generator_)
<class 'generator'>
2、生成器也是迭代器
# 以上略...
>>> generator_ = my_generator()
# 可发现 __iter__ 与 __next__ 方法
>>> dir(generator)
[..., '__iter__', '__le__', '__lt__', '__name__', '__ne__', '__new__', '__next__', ..., 'send', 'throw']
3、传统方式获取生成器的元素
# 以上略...
>>> generator_ = my_generator()
>>> next(generator_)
0
>>> next(generator_)
1
>>> next(generator_)
2
>>> next(generator_)
3
>>> next(generator_)
4
>>> next(generator_)
# 终止迭代则会抛出 StopIteration 异常
Traceback (most recent call last):
File "<input>", line 1, in <module>
StopIteration
4、使用 for 循环获取生成器元素
# 以上略...
>>> generator_ = my_generator()
>>> for num_ in generator_:
print(num_)
0
1
2
3
4
5、生成器表达式与列表生成式
聊到这,大家不妨思考一下,我们为什么要使用生成器?
我们以一个简单例子来对比一下,两者实现相同功能的内存消耗。
使用列表生成式获取一个包括 100 万个元素的列表,借用 sys 模块计算内存
>>> import sys
>>> my_list = [i for i in range(1000000)]
# 调用 sys.getsizeof() 获取内存消耗
>>> print("列表消耗的内存:{}".format(sys.getsizeof(my_list)))
列表消耗的内存:4348736
下面,我们看看生成器表达式
>>> import sys
>>> my_generator = [i for i in range(1000000)]
>>> print("生成器消耗的内存:{}".format(sys.getsizeof(my_generator)))
列表消耗的内存:56
很明显,对于相同数量的项,列表生成式和生成器在内存消耗上存在巨大差异,这就是我们为什么要使用生成器的原因。
应用 - 使用 yield 实现斐波那契数列¶
斐波那契数列(Fibonacci sequence),又称黄金分割数列、因数学家列昂纳多·斐波那契(Leonardoda
Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”。
指的是这样一个数列:1、1、2、3、5、8、13、21、34、……在数学上,斐波纳契数列以如下被以递推的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)
今天,我们使用 Python 中的 yield 来实现
>>> def fibonacci(n):
"""斐波那契数列实现"""
a, b = 0, 1
while n > 0:
a, b = b, a + b
n -= 1
yield a
# 获取斐波那契数列前 10 个成员
>>> fibonacci_ = fibonacci(10)
for i in fibonacci_:
print(i)
1
1
2
3
5
8
13
21
34
55
扩展 - itertools 库简介¶
itertools
中的大多数函数是返回各种迭代器对象,如果自己去实现同样的功能,代码量会非常大,而在运行效率上反而更低,因此,我们很有必要了解一下这个标准库。

获取指定数目内正整数的累加和
>>> import itertools
# 获取 10 以内的正整数累加和
>>> cumulative_sum = itertools.accumulate(range(10))
# 转换为列表
>>> print(list(cumulative_sum))
[0, 1, 3, 6, 10, 15, 21, 28, 36, 45]
获取指定数目元素的所有排列(顺序有关)
>>> import itertools
# 获取元素 1、2、3 的所有排列结果
>>> array_result = itertools.permutations((1, 2, 3))
# 转换为列表
>>> print(list(array_result))
[(1, 2, 3), (1, 3, 2), (2, 1, 3), (2, 3, 1), (3, 1, 2), (3, 2, 1)]
总结¶
迭代器属于可迭代对象,生成器是特殊的迭代器。
可迭代对象都构建了
__iter__方法,迭代器还需构建__next__()方法。生成器是一种特殊的迭代器,内部支持了生成器协议,不需要明确定义
__iter__方法和__next__()方法。列表生成式的效率远高于 for 循环语句嵌套,生成器的效率远高于列表生成式。
获取可迭代对象的元素时,强烈推荐 for 循环,因为它具备自动处理异常的能力。
Python 中,包含 yield 关键词的普通函数就是生成器。
文中难免会出现一些描述不当之处(尽管我已反复检查多次),欢迎在留言区指正,也可分享迭代器、与生成器相关的技巧、以及有趣的案例。
原创文章已全部更新至 Github :https://github.com/kelepython/kelepython
本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c01/c01_11.html
1.12 浅谈 Python 中的函数¶
0. 前言
真实开发工作中,有很多朋友拿到需求立马就动手去实现,甚至不愿意多花一分钟去设计自己的程序。
于是,写着写着,很自然地就出现了很多冗余的代码段,甚至有些代码段非常类似,处理逻辑基本相同。
程序员小王一看需求太开心拉,直接拷贝下来稍作调整就完事,可以开心地去泡杯咖啡了。
其实,对于业务逻辑相近,代码重复率高的情况,我们可以通过 函数
的封装来减少我们程序中冗余的代码,只需传递不同的 参数
给函数,便能实现不同的处理过程,进一步提升开发效率。
1. 什么是函数
那么,什么是 Python 的函数呢?
函数是组织好的,可重复使用的,用来实现单一、或相关联功能的代码段。
函数包括
声明关键词、函数名、函数体、返回值、参数五部分,当然,函数也可以没有返回值与参数。
你看,函数就是我们抽取出来的一段代码,只不过是根据我们自己的需求做了一些包装,并且给它取了个新的名字而已。
在 Python 中,我们一般使用 def
关键词声明,后面紧接着是函数标识符名称与圆括号 -
(),最后接一个冒号 - :,函数体
必须有缩进,业务逻辑便是在函数体中实现的,我们调用函数只需要使用函数名 +
小括号即可。
def my_func():
"""我定义的函数"""
print("这里是函数体")
my_func() # 函数调用
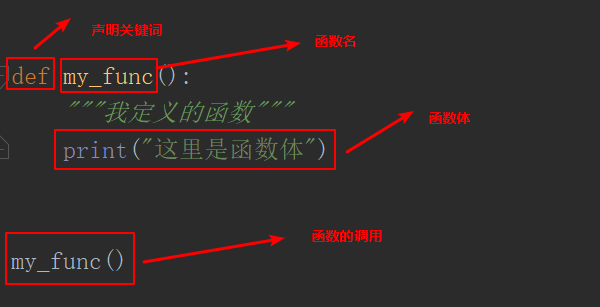
函数1.jpg¶
2. 函数的优势
函数的优势也非常明显,它能提高我们程序的模块性与代码的重复利用率。
在实现业务逻辑时,我们只需调用对应的功能函数去实现,可避免代码的冗余,让程序代码结构更加清晰、更易于维护。
这也是 Python 的强大之处,开发者已经帮我们封装好了很多内置的函数,在实现相关的需求时,我们只需调用对应的函数即可。
3.函数的细分
函数可分为内置函数与自建函数,有参数与无参数的函数,有返回值与无返回值函数以及有名称与无名称的函数等等,我们今天主要讨论自建函数,也就是我们自己声明的函数。
3.1 有无参数的函数
我们通过实现两数之和的函数来演示两者的区别。
定义一个无参数的计算两数之和的功能函数,并将计算结果返回,函数中使用
return 语句返回数据。
def add_func():
"""计算两数之和"""
a = 1
b = 2
return a + b
add_result = add_func()
print(add_result) # 3
我们可以发现这个函数只能计算 1+2
的结果,这难免太过于死板,我们可以改得灵活一些,计算传递进来的两数之和。
def add_func_plus(a, b):
"""计算两数之和"""
return a + b
add_result = add_func_plus(3, 4)
print(add_result) # 7
你看,这就是带参数的函数与不带参数的函数的区别,前者更加灵活,适用范围更加广泛。
3.2 有无返回值的函数
函数的返回值可有可无,设计者根据需求来决定,我们通过实现判断传入参数是否是
回文 的功能函数来演示两者的区别。
顺序与逆序读取的内容是相同的,就说明此数据为回文。
定义一个带参数的判断传入参数是否是回文的功能函数。
def is_palindrome(str_data):
"""判断是否是回文"""
str_ = str_data[::-1]
if str_data == str_:
return_data = "是回文"
else:
return_data = "不是回文"
print(return_data) # 是回文
is_palindrome("上海自来水来自海上")
我们可以发现,在函数打印出来的判断结果是回文,但是假设我们需要根据此判断来做后续的业务逻辑呢?
若不将判断结果返回的话,我们在函数外部就不知道这个数据到底是不是回文,当然也有其他的方式实现,我们这里不做考虑。
def is_palindrome(str_data):
"""判断是否是回文"""
str_ = str_data[::-1]
if str_data == str_:
return_data = "是回文"
else:
return_data = "不是回文"
return return_data
result_dada = is_palindrome("上海自来水来自海上")
if result_dada == "是回文":
print("这里是回文的业务逻辑")
你看,我们将判断的结果返回,这样在函数外部便可通过返回的结果,做后续的业务逻辑处理,后者才能更加透彻为我们的程序服务,起到实质性的帮助。
当然,函数还支持返回多个返回值,如定义一个函数返回传递两个参数的和与积。
def return_two(a, b):
"""计算两数之和与两数之积"""
return a+b, a*b
first_result, second_result = return_two(3, 4)
print(first_result, second_result) # 7 12
3.3 有无名称的函数
上面例子中的函数都是拥有自己名称的,在 Python
中还有没有名字的函数,我们称之为 匿名函数 ,Python 中使用 lambda
关键字来声明匿名函数。
我们定义一个计算数字平方的函数:
lambda_func = lambda x: x ** 2
print(lambda_func(2)) # 4
使用 def 定义相同功能的函数:
def def_func(x):
return x**2
print(def_func(2)) # 4
通过这个例子还看不出匿名函数的强大之处,下面我们结合内置函数 - map
来计算存放10个数字的列表的每一个数字的平方,并返回一个新的列表。
使用 def 定义功能函数:
def def_func():
return_list = []
for i in [x for x in range(100)]:
return_list.append(i**2)
return return_list
print(def_func())
# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
使用 lambda + map 函数定义:
print(list(map(lambda x: x**2, [x for x in range(10)])))
# [0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
在开发中还有很多场景可以使用匿名函数来简化代码,后面会发现还是蛮有意思!
4.函数应用之笑话生成器
我们声明一个笑话生成器的函数,每次调用函数都会生成不一样的笑话,在学习工作之余,大家乐一乐,放松放松。
1、定义笑话生成器函数,这里使用 Python 中第三方库 requests
实现笑话的获取。
import requests
def get_joke():
"""笑话生成器"""
# 1. 笑话获取接口 URL
url = "https://autumnfish.cn/api/joke"
# 2. 获取返回数据
joke_data = requests.get(url)
# 3. 解析数据并返回
return joke_data.text
joke_ = get_joke()
print(joke_)
2、调用笑话生成器函数,并打印获取到的内容。
# 调用笑话生成器函数
joke_ = get_joke()
print(joke_)
获取的笑话内容示例一:
一个四岁的男孩亲了三岁的女孩一口!
女孩对男孩说:“你亲了我可要对我负责啊。”
男孩成熟地拍了拍女孩的肩膀,笑着说:“你放心,我都四岁了,又不是一两岁的小孩子了”
获取的笑话内容示例二:
小学二年级的时候,我妈说要把我卖掉,我妈的语气特别真实。我当真了,上学的时候哭着告诉了我们班长。
班长也很着急,放学后帮我叫了全班同学到我家里,求我妈不要把我卖掉。当一大片孩子跪倒在地的时候,正在打麻将的我妈彻底震惊了…
5.总结
1、Python 中的函数声明有严格的格式要求,声明时需要特别注意格式。
2、灵活设计好参数与返回值,函数会给你带来意想不到的惊喜,有兴趣的朋友可研究下源码,学习下开发者的函数设计理念与设计逻辑。
3、匿名函数建议去熟悉、练习一下,结合其他函数使用,可以大大简化我们的代码结构。
4、原创文章已全部更新至 Github:https://github.com/kelepython/kelepython
5、本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c01/c01_12.html
6、欢迎在留言区讨论,有任何疑问也可与小编联系,也欢迎大家分享一些有趣的案例。
1.13 浅谈 Python 中的模块¶
0. 前言
真实项目开发中,我们会对项目的常量、变量、以及函数进行统一管理,把这些声明、定义放在一个以
.py 结尾的文件中,我们将这个文件称为 模块。

简单来讲,模块是一个包含所有我们自己定义的函数和变量的 Python
文件,模块可以在需要的地方通过 import
语句导入,以使用该模块中的常量、变量、函数等,Python
也为我们提供了很多标准的模块。
当解释器遇到 import 语句时,如果模块在当前的搜索路径中就会被导入,多次导入一个模块时,只有最后一次生效,这样可以防止导入模块被多次执行。
搜索路径存储在 sys 模块中的 path
变量中,我们可以通过以下代码查看。
import sys
print(sys.path)
其实,将项目代码模块化,可在一定程度上优化项目结构,避免单个 Python 文件代码过多的情况,提高代码可读性。
1. 模块分类
Python 中的模块供分为三类,即内置模块、第三方模块、以及自定义模块。
1.1 内置模块
内置模块是 Python 官方开发者帮我们设计好的,安装好 Python 环境我们就可以直接使用这些内置模块,比较常用的有以下模块:
os:包含普遍的操作系统功能
sys:提供了一系列有关 Python 运行环境的变量和函数
random:用于生成随机数
time: 主要包含各种提供日期、时间功能的类和函数
datetime:对 time 模块的一个高级封装
logging:日志处理
re:用于实现正则匹配
json:用于字符串和数据类型间进行转换json
1.2 第三方模块
第三方模块是 Python 开发者提前开发好的模块,需要安装对应的库才能使用该模块中的函数等,工作中比较常用的有以下第三方模块:
requests:常用的 http 模块,常用于发送 http 请求
scrapy:在网络爬虫领域必不可少
pygame:常用于 2D 游戏的开发
numpy:为 Python 提供了很多高级的数学方法
Flask:轻量级开源 Web 开发框架,灵活、开发周期短
Django:一站式开源 Web 开发框架,遵循 MVC 设计
1.3 自定义模块
自定义模块是我们自己根据实际需求开发的模块,通常是对某段逻辑或某些函数进行封装,供其他函数调用,使用时我们需要将其引入到我们的项目中。
需要注意的是,自定义模块的命名一定不能与内置模块重名,否则会将内置模块覆盖。
例如:我们自定义了一个 os.py 的模块,这是我们使用 import
语句引入的 os 模块就是我们自己定义的这个模块,不再是内置的 os 模块。
内置模块与第三方模块还有很多,大家可以通过搜索引擎去了解、学习。
2.模块的引入方式
在使用模块时,我们根据不同的需求,会有三种引入方式,一是使用 import
语句,二是使用 from ... import ... 语句,三是使用
from ... import * 语句。
那么,这三种方式存在什么区别呢?我们接着往下看。
我们将上篇文章中的 笑话生成器 函数封装至自定义模块 my_demo.py
中,代码如下:
import requests
author = "可乐python说"
def get_joke()->str:
"""笑话生成器"""
# 1. 笑话获取接口 URL
url = "https://autumnfish.cn/api/joke"
# 2. 获取返回数据
joke_data = requests.get(url)
# 3. 解析数据并返回
return joke_data.text
2.1 import 语句
我们可以看到,前面的案例中使用 import 语句引入了 requests
模块,这就意味着将这个模块所有资源全部导入至我们项目中,通过模块名 +
. 的方式来使用所需要的资源。
这里我们使用 requests.get(url) 来调用模块中的 get 方法来实现一个
http get 请求,同理,我们也可在其他地方调用我们自定义模块中的笑话生成器函数。
创建 demo.py 文件,内容如下:
# 导入模块
import my_demo
# 使用模块名调用 get_joke 函数
joke_text = my_demo.get_joke()
print(joke_text)
执行 demo.py 文件可成功获取笑话内容,输出内如下:
以前住一个大院,院里有一个公共厕所,为了防止外面的人进去方便就上了一把锁,仅供院里的人用。
一次上厕所,邻居一女孩领一女同学也来,那同学好奇的问:“你们厕所还上锁,难道怕有人偷便便吗?!”
2.2 from ... import ... 语句
当我们只需要使用到模块中的部分资源时,全部导入未免过于消耗资源,这时我们可以使用
from ... import ... 语句。
假设 my_demo.py 模块中还定义了很多函数、变量,而我们只需要使用
author 这个变量,可使用以下代码实现:
# 导入模块中的 author 变量
from my_demo import author
# 使用 author 变量
print(author)
输出内容如下:
可乐python说
你看,这就是区别。
2.3 from ... import * 语句
当我们需要使用模块中所有的资源是,可以使用 from ... import *
语句来实现,实现代码如下:
# 导入模块中的所有资源
from my_demo import *
# 使用 author 变量
print(author)
# 调用 get_joke 函数
joke_text = get_joke()
print(joke_text)
输出内容如下:
可乐python说
“老公,我的卷发棒在哪啊?”
“棒就棒在和你的气质特别配。”
你看,通过这种方式导入资源,使用变量名、函数即可直接使用资源。
3.几种导入方式的区别
通过以上例子我们不难发现,不同的导入方式,在使用资源时存在一定差异。
import 语句导入的是一个模块,相当于导入一个 文件夹 ,属于
相对路径
,并将整个模块中的代码执行一遍,并没有在当前命名空间中导入定义的变量,使用资源时需要使用
模块名 + . 的方式。
什么是 命名空间 ?
命名空间是当前定义的符号名称以及每个符号名称所引用的对象的信息的集合。
可以将命名空间视为字典,其中键是对象名称,值是对象本身。每个键值对将一个名称映射到它所对应的对象。
import ... from ... 语句则相当于导入模块中具体的资源,并将资源直接导入了当前的命名空间,使用时直接使用资源名称即可。
import ... from * 语句与 import ... from ... 类似,但不建议使用,使用这类语句会破坏命令空间的管理,会给我们带来一些麻烦。
4.总结
1、Python 中的模块十分常用,开发者根据实际需求在内置模块、第三方模块还是自己实现中选择。
2、自定义模块的命名与标识符规则一样,但需注意不要与内置、第三方模块重名否则会被覆盖。
3、尽量不要使用 import ... from * 语句,使用该语句时,不能导入模块中前缀为
单下划线的保护属性与前缀为双下划线的私有属性。4、原创文章已全部更新至 Github:https://github.com/kelepython/kelepython。
5、本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c01/c01_13.html。
6、欢迎在留言区讨论,有任何疑问也可与小编联系,也欢迎大家分享一些有趣使用的知识。
第二章:技术笔记¶
这二章主要记录学习、工作中的一些技术笔记
本章节,会持续更新,敬请关注...
2.1 Centos 使用 pyinstaller 打包踩坑分享¶
前言¶

最近,在 Centos 7 虚拟机上面搭建了
Python3环境、以及虚拟环境,以后需要在此环境中进行打包。
今天尝试安装 Pyinstaller
,并进行打包,安装过程非常顺利,执行一下命令即可。
pip3 install pyinstaller
准备测试文件 demo.py ,内容如下:
print("hello python")
但使用以下命令打包测试代码时会报错
pyinstaller -F demo.py
现将具体处理过程记录下来
报错提示¶
执行打包命令后,报错信息如下:
...前面内容已经省略
* On Debian/Ubuntu, you would need to install Python development packages
* apt-get install python3-dev
* apt-get install python-dev
* If you're building Python by yourself, please rebuild your Python with `--enable-shared` (or, `--enable-framework` on Darwin)
* (demo) [root@group demo]# This would mean your Python installation doesn't come with proper library fi les.
> This usually happens by missing development package, or unsuitable build par ameters of Python installation.
提示的信息大致说,缺少相关动态库,
1、如果在 Debian/Ubuntu 上,您需要安装Python开发包 * apt get 安装
python3 dev * apt get 安装 python dev
2、如果你是自己构建 Python ,请使用 “-enable shared”
重新构建Python(或者在 Darwin 上使用 --enable framework)
3、这意味着你的 Python 安装没有正确的库文件,这通常是由于缺少开发包,或者 Python 安装的构建参数不合适而导致的。
第一处报错处理¶
1、进入 Python 编译目录
cd Python-3.7.2/
2、带上参数 --enable-shared 重新编译
./configure --prefix=/usr/local/python3 --enable-shared --with-ssl
3、重新安装
make && make install
编译、安装过程非常顺利,很开心,下面检验一下 Python 是否能正常使用
4、运行 python3 ,出现一个新的报错 -
error while loading shared libraries
python3
具体报错信息如下:
python3 :error while loading shared libraries :libpython3.7m.so.1.0:cannot open shared object file:No such file or directory.
第二处报错处理¶
分析报错信息,运行时链接动态库失败导致的报错
1、查看编译时安装 libpython3.7m.so.1.0 动态库的目录
find /usr -name 'libpython3.6m.so.1.0'
输出如下信息
/usr/local/python3/lib/libpython3.7m.so.1.0
则安装该动态库的目录为 /usr/local/python3/lib,
2、使用链接器查看可搜索范围,并没有发现 libpython3.7m.so.1.0
ldconfig -v | grep python3
执行以下命令也可发现,这个库的指向为 not found
ldd $(which python3)
根据资料说明,链接器默认的动态库搜索范围包括 /lib 、/usr/lib
以及 /etc/ld.so.conf
配置文件中包含的目录,这是我们处理问题的突破口。
3、手动将该库的安装目录 - /usr/local/python3/lib/, 添加到
/etc/ld.so.conf 中
vi /etc/ld.so.conf
编辑后的内容如下:
include ld.so.conf.d/*.conf
/opt/openssl1.0.2r/lib
/usr/local/python3/lib
4、执行 ldconfig 刷新缓存
ldconfig
5、检验命令 python3 ,可正常使用
python3
6、再次使用 pyinstaller 打包测试代码
pyinstaller -F demo.py
打包成功
... 以上打包提示信息已省略
20945 INFO: Building EXE from EXE-00.toc completed successfully.
7、进入当前目录下的 dist 目录中,执行刚刚生成的打包文件 demo
cd dist/
./demo
成功输出 hello python,至此所有报错问题已全部处理,下面可开心愉快地对项目进行打包咯。
总结¶
之前我们编译的方式,没有加上
--enable-shared参数,为静态编译,而打包时又需要使用到一些动态库,所以我们调整为使用动态编译的方式,重新编译了 Python3 环境,成功处理了第一处报错。编译后,运行
python3命令时找不到我们安装的相关动态库,因为系统只会在默认的范围中寻找,我们手动将动态库的安装目录添加到/etc/ld.so.conf文件中,成功处理第二处报错。添加动态库安装目录后,记得刷新一下缓存。
原创文章已全部更新至 Github :https://github.com/kelepython/kelepython
本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c02/c02_01.html
环境的安装,往往会遇到一些坑,不过只要我们脚踏实地,认真记录好自己工作、学习中遇到的一些小问题,积累下来,将会变成一笔宝贵的财富。
第三章:Python 实战¶
这三章主要分享学习、工作中的一些实战案例
本章节,会持续更新,敬请关注...
3.1 实战 | 手把手带你从零搭建永久免费个人博客¶
0. 前言¶
很喜欢一句话,“好记性不如烂笔头”,一直以来,我都有写技术笔记的习惯,将自己学习的知识、遇到的问题、处理方案等记录下来,长期积累下去,也将是一笔宝贵的财富。
以前在博客园、CSDN上写过文章,也曾有过搭建个人博客的想法,之前尝试过几个模板,使用
Python 实现,不过后续由于种种原因中途放弃了。
上段时间在 知乎
上看到一篇关于博客搭建的文章,写得挺详细,原文使用的环境是 Python
2.7.14,我使用 Python 3.6.8
搭建了一个属于自己的永久免费技术博客。
其实,我在 2020 年 4 月 20 日就完成了个人博客的搭建,期间也踩了不少坑。时隔近半年的今天,在踩了众多坑之后,我精心总结,毫无保留地将所有的操作步骤分享给大家。
1. 博客预览¶
这是我的个人技术博客 (kelepython.readthedocs.io) ,大家先预览一下效果。
1、首页,可看到所有文章的索引
2、前言页面
3、点击对应文章索引,可进入文章预览页面
4、还支持关键词检索,如在左侧搜索栏输入 Python
回车,检索内容会高亮展示
2. 环境和库¶
本文使用 Typora + Sphinx + GitHub + ReadtheDocs 来实现个人博客的搭建、文章撰写以及管理。
Typora : Markdown 编辑器,用于转写文章
Sphinx :生成博客网页
GitHub :托管博客项目
ReadtheDocs :构建、发布网页
3. 相关环境准备¶
1、安装 Python 3.6.8 环境,请自行下载安装(网上有很多相关教程)。
2、运行如下命令,安装 Sphinx 。
pip install sphinx sphinx-autobuild sphinx_rtd_theme
3、创建项目根目录 myblog,并执行 sphinx-quickstart
初始化项目,输入项目相关配置项。
4、完成后,项目目录结构如下所示:
PS F:\learning\myblog> tree /f
文件夹 PATH 列表
卷序列号为 0EDB-3039
F:.
│ make.bat
│ Makefile
│
├─build
└─source
│ conf.py
│ index.rst
│
├─_static
└─_templates
5、完成项目配置及扩展,配置文件为 source/config.py
,为了快速搭建博客,关注微信公众号 「可乐python说」,后台回复
个人博客 即可获取。
6、配置文件的使用还需要搭配扩展模块才能正常使用,获取压缩包之后,将里面的
exts 文件夹拷贝到 source 同级目录(项目根目录)下即可。
7、安装第三方依赖包,我已全部写入压缩包中的 requirements.txt
文件中,你只需执行以下命令安装即可完成批量安装,并将此 txt
文件拷贝到项目根目录下。
pip install -r requirements.txt
至此,准备工作已基本完成,下面可以开始创作了。
4. 撰写文章¶
1、在 source 目录下新建名为 language_introduction.rst 的文件。
2、写入如下内容并保存。
第一章 语言介绍
======================
1.1 Python
---------------------
Hi, 我叫 Python...
1.2 Java
---------------------
Hi, 我叫 Java...
3、写完文章后,我们还需将文章写入排版配置文件 source\index.rst
中,内容如下,注意一定要有空行,其他内容均可删除。
以上略...Welcome to myblog's documentation!==================================.. toctree::
:maxdepth: 2
:caption: Contents:
language_introduction
4、在根目录下执行 .\make html 生成静态页面 。
5、执行完之后,生成的静态页面保存在 \build\html
目录下,我们可使用浏览器打开 index.html 验证效果 。
是不是很激动?我第一次看到网页效果的时候也非常激动。
至此,本地项目已经完成,但这仅仅是我们本地的效果,要让读者能够访问我们的博客,还需要将博客发布上线。
5. 托管项目¶
选择 GitHub 托管项目, 在 push
项目之前,我们需要在项目根目录下添加忽略文件
.gitignore,内容如下:
build/
.idea/
*.pyc
在 GitHub 上新建一个仓库,在本地配置好 Git
的相关配置项,然后将整个项目 push 到远程仓库中, Git
相关的操作请自行查阅相关文档实现。
6. 发布上线¶
要想别人通过公网访问我们的博客,还需要将项目发布上线,本文使用
Read the Docs 发布,请进入官网:https://readthedocs.org/。
1、你需要先注册、登陆、然后关联你的 GitHub
博客项目代码仓库,输入项目相关信息后,点击下一页
2、点击 Build version 构建项目版本
3、耐心等待,当看到 构建完成 时表示此版本构建成功
4、待构建完成之后,点击概况,我们可以在 短网址
栏看到我们的公网地址
5、没错这就是我们博客的访问地址,赶紧复制下来,去浏览器访问你的个人博客
7. Markdown 转换¶
至此,我们就完成了个人博客的搭建,但是这种撰写文章的方式很不习惯,如果你也和我一样,日常使用 Markdown 编辑器 - Typora 写文章的话,请接着往下看。
当然,你也可自行配置使用何种格式的文件构建博客项目,具体的配置可前往文末的相关官网网站研究。
1、写文章之前我们需要下载、安装 Markdown 编辑器 -
Typora,请前往官网https://www.typora.io/下载。
2、下载完之后我们可编写一个简单的 preface.md 文件,内容如下:
前言
关于博客
这个网站是我的首个博客,博客名字叫《可乐python说》,此博客于2020年4月20日发布完成,使用的是 Sphinx 来生成文档,使用 Github 托管文档,并使用 Read the Doc 发布文档。
3、对于格式转换,原文使用的 pandoc
实现,你只需安装、执行相应的命令即可,本文使用代码实现,转换代码,我已为你准备好,一并放在压缩包资料中。
4、运行压缩包里面的 md_to_rst.py 文件可将 .md 文件转换为
.rst 格式的文件 ,运行完之后会在项目根目录下生成 preface.rst
文件,接下来就可使用 Git 同步本地项目到远程仓库。
5、同步文章至远程仓库后,按照上述步骤,构建项目,即可更新博客。
6、切记一定要更新配置文件 source\index.rst ,内容如下
以上略...Welcome to myblog's documentation!==================================.. toctree::
:maxdepth: 2
preface
language_introduction
7、更新完的博客页面如下,我们新增了前言页面,去掉了默认的目录配置
:caption: Contents:
8. 总结¶
使用不同的 Python 版本,对应的第三方依赖的版本也有所不同,具体的坑需要你自行尝试。
本文使用 Python 3.6.8 ,踩坑之后发现,需指定第三方依赖版本,否则会构建失败,对应依赖包的版本我已全部提供在压缩包的
requirements.txt文件中。Github 远程仓库的项目必须公开,否则会构建失败。
搭建步骤较多,但难度不大,建议按照教程一步步实现,每个步骤对后面的操作都会存在影响,切记一定细心,否则会构建失败。
不要怕报错,可乐也是踩了很多坑,最后才完成博客搭建的,有疑问、或者相关的建议、技巧请在评论区留言、交流、分享。
完整资料,请扫码关注下方微信公众号,后台回复 「个人博客」 领取。
sphinx支持定制化配置,具体介绍请前往官网学习,https://www.sphinx-doc.org/en/master/index.html。目录索引排版配置文件的具体介绍请前往 https://www.sphinx-doc.org/en/master/usage/restructuredtext/directives.html#directive-toctree 学习。
原创文章已全部更新至 Github:https://github.com/kelepython/kelepython。
本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c03/c03_01.html
3.2 实战 | Python 实现 AI 语音合成技术¶
0. 前言
如今,语音识别、语音合成
等技术在各行各业得到广泛应用,各种大厂平台也顺势发展,对各类流行开发语言的支持也十分友好。
今天我将选择 百度云 作为案例演示平台,使用 Python
开发语言实现语音合成的小案例。
1. 语音合成技术
语音合成(speech synthesis)是通过机械的、电子的方法产生人造语音的技术。
TTS技术(又称文语转换技术)隶属于语音合成,它是将计算机自己产生的、或外部输入的文字信息转变为可以听得懂的、流利的汉语口语输出的技术。
简单来说,就是可以将我们的文字信息,转换成音频数据,我们可以以文件的形式保存,为后续的使用提供便利。
2.案例实现
2.1 API 设计
案例的API设计如下:
if __name__ == '__main__':
app_id = '应用 ID'
api_key = 'API 开发密钥'
secret_key = '密钥'
AipSpeech(app_id, api_key, secret_key).main()
3.实现流程
3.1 准备工作
1、进入百度云官网 https://cloud.baidu.com/,并注册、登陆。
1.百度云首页.png¶
2、进入控制台页面,选择语音技术,并点击 创建应用。
2.语音技术.png¶
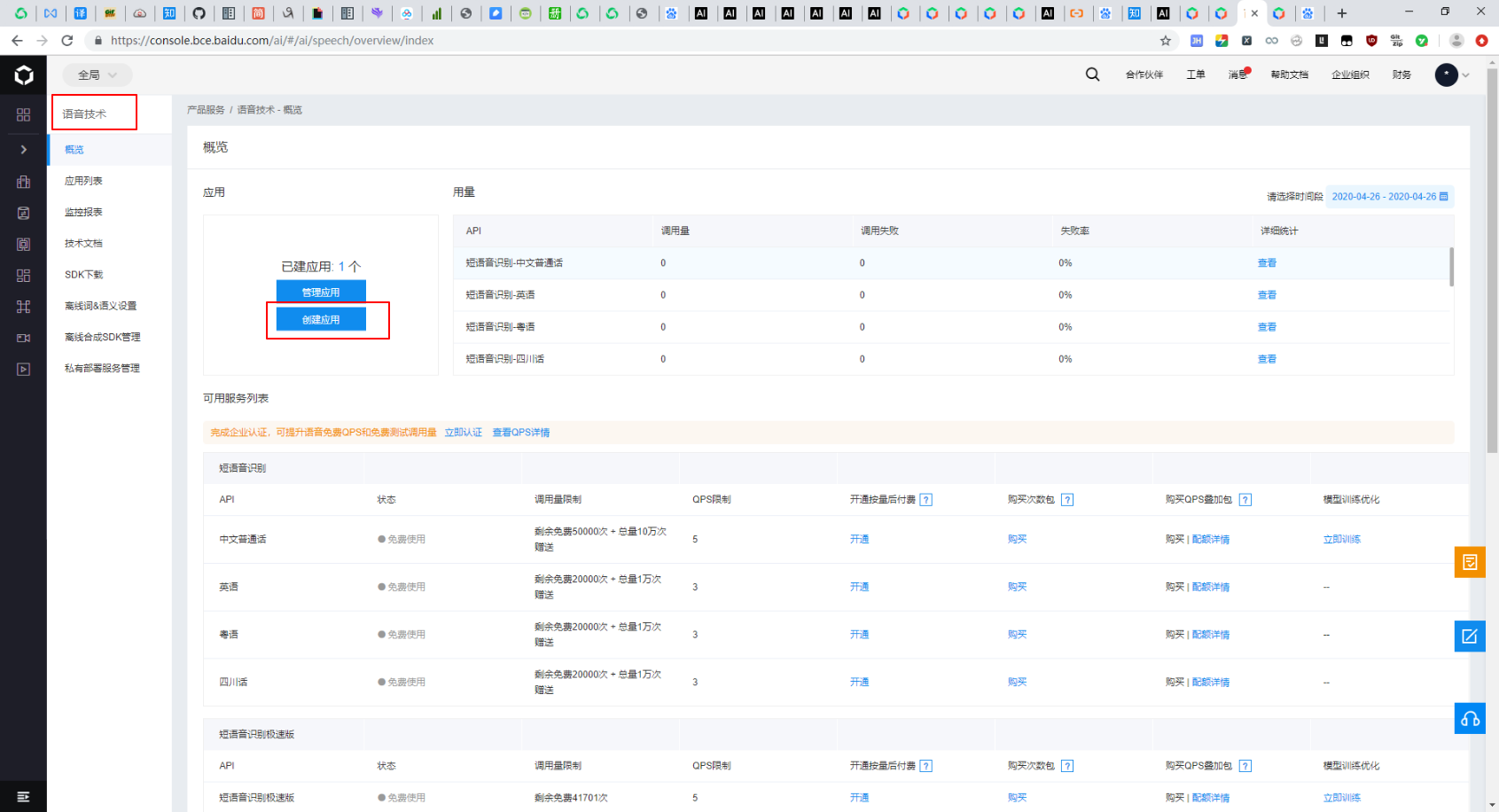
2.1.创建应用.png¶
3、填写相关信息后点击,立即创建。
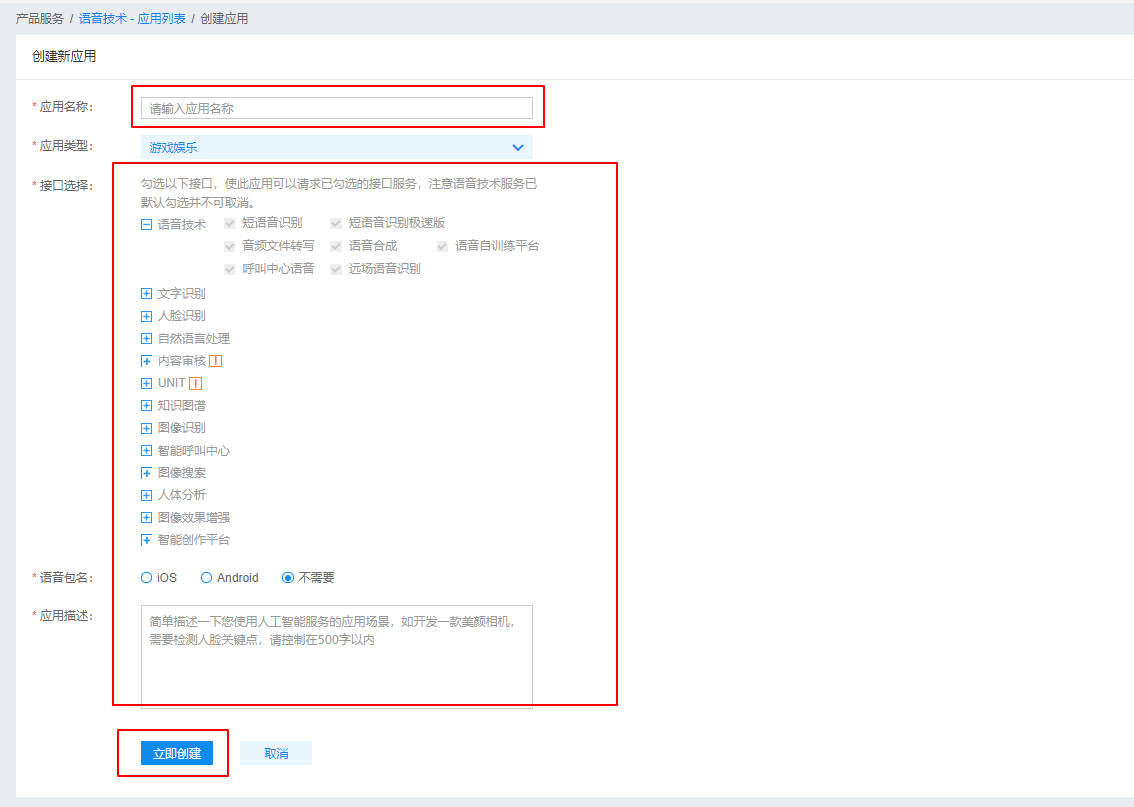
3.描述应用.png¶
4、创建完毕后,就可管理刚刚创建的应用,查看 应用ID、密钥 等参数。
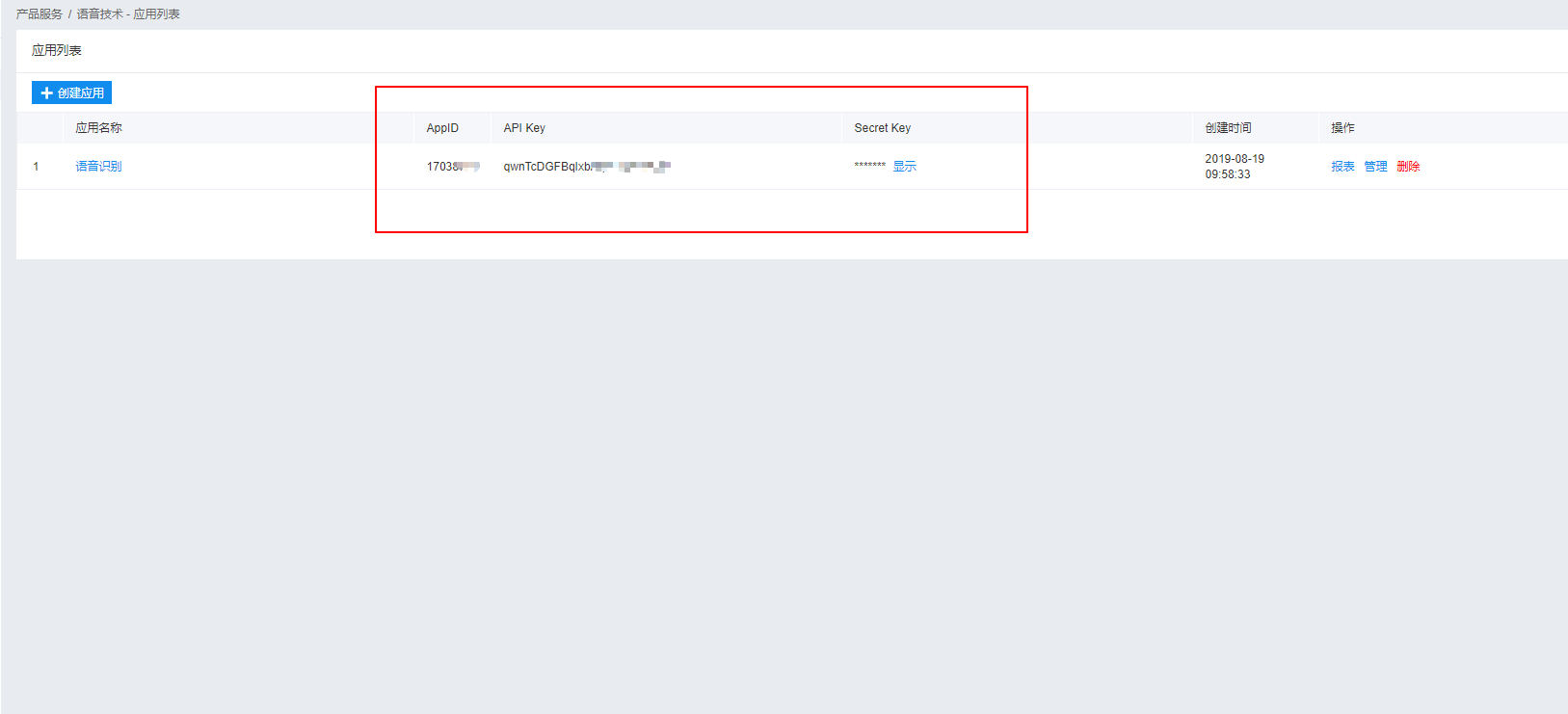
4.管理应用.png¶
5、进入 SDK 资源网页,下载在线合成 Python-SDK 压缩文件。
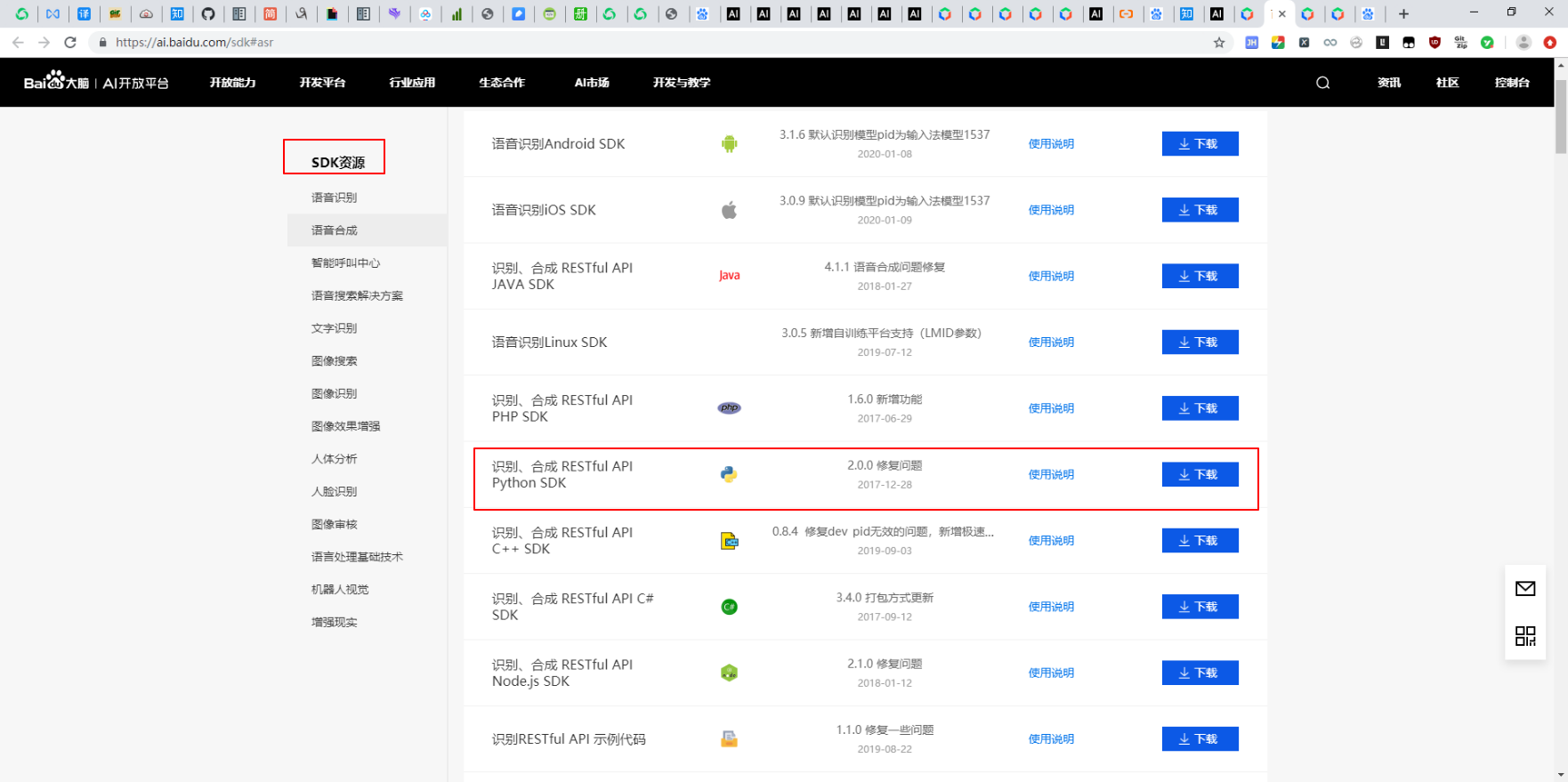
5.SDK.png¶
6、解压后的 SDK 中的 api 目录结构如下图,具体实现可参考 接口说明 。
SDK目录.png¶
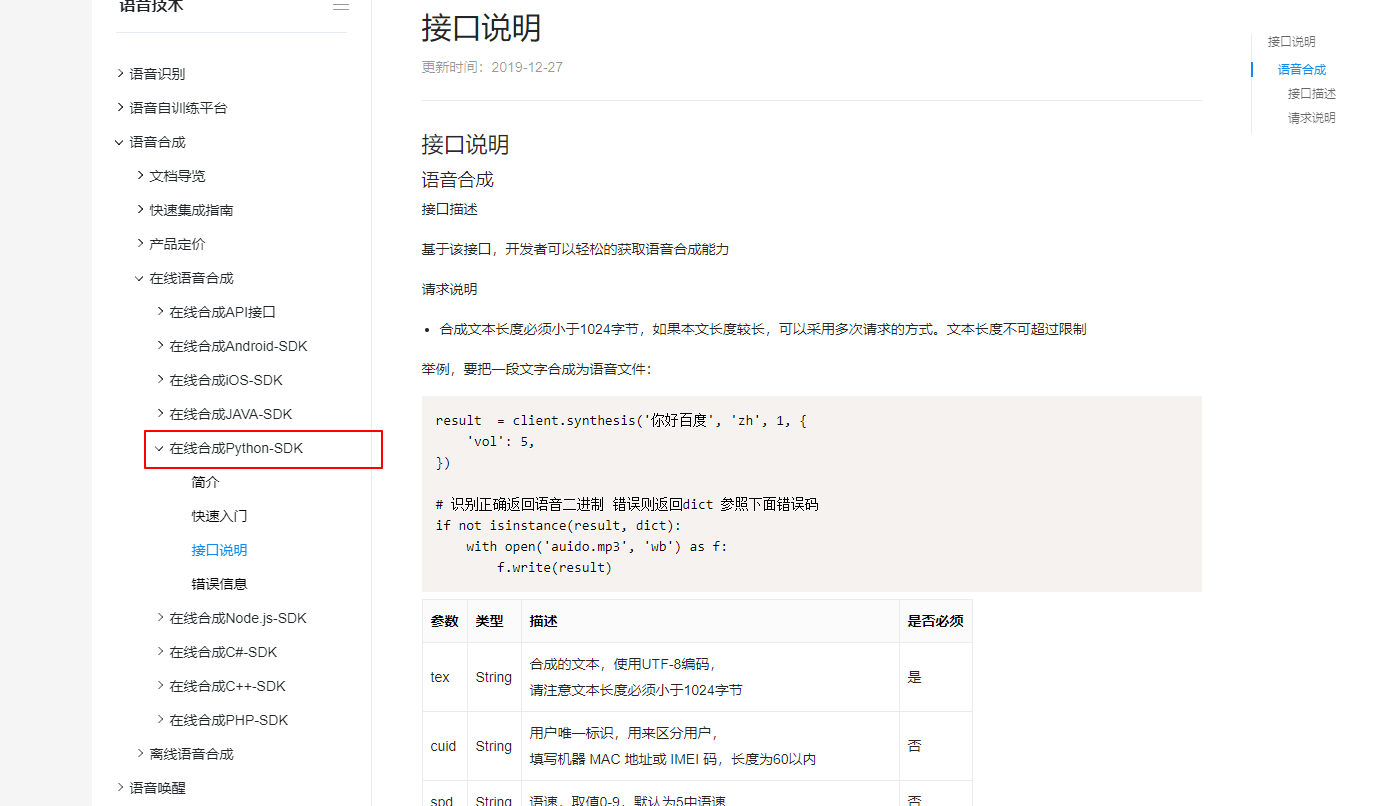
6.接口说明.png¶
3.2 API 封装、改写
为了方便使用,我们可对 SDK 进行封装,改写部分内容。
1、新建 baidu_speech_synthesis.py 文件。
# -*- coding: utf-8 -*-
"""
Speech_Synthesis
"""
import base64
import hmac
import json
import hashlib
import datetime
import time
import sys
import requests
2、将 base.py 文件中 AipBase 类的相关代码拷贝到刚刚创建的
baidu_speech_synthesis.py 文件中,删除 python2 的相关写法。
# 以上略
class AipBase(object):
"""
AipBase
"""
__accessTokenUrl = 'https://aip.baidubce.com/oauth/2.0/token'
__reportUrl = 'https://aip.baidubce.com/rpc/2.0/feedback/v1/report'
__scope = 'brain_all_scope'
def __init__(self, app_id, api_key, secret_key):
"""
AipBase(app_id, api_key, secret_key)
"""
self._app_id = app_id.strip()
self._api_key = api_key.strip()
self._secret_key = secret_key.strip()
self._auth_obj = {}
self._is_cloud_user = None
self.__client = requests
self.__connect_timeout = 60.0
self.__socket_timeout = 60.0
self._proxies = {}
self.__version = '2_0_0'
def get_version(self):
"""
version
"""
return self.__version
def set_connection_timeout_in_millis(self, ms):
"""
set_connection_timeout_in_millis
建立连接的超时时间(单位:毫秒)
"""
self.__connect_timeout = ms / 1000.0
def set_socket_timeout_in_millis(self, ms):
"""
set_socket_timeout_in_millis
通过打开的连接传输数据的超时时间(单位:毫秒)
"""
self.__socket_timeout = ms / 1000.0
def set_proxies(self, proxies):
"""
proxies
"""
self._proxies = proxies
# 由于代码量大,以下略...
3、将 speech.py 文件中 AipSpeech 类的相关代码拷贝到刚刚创建的
baidu_speech_synthesis.py 文件中。
# 以上略
class AipSpeech(AipBase):
"""
Aip Speech
"""
__asrUrl = 'http://vop.baidu.com/server_api'
__ttsUrl = 'http://tsn.baidu.com/text2audio'
def _is_permission(self, auth_obj):
"""
check whether permission
"""
return True
def _proccess_request(self, url, params, data, headers):
"""
参数处理
"""
token = params.get('access_token', '')
if not data.get('cuid', ''):
data['cuid'] = hashlib.md5(token.encode()).hexdigest()
if url == self.__asrUrl:
data['token'] = token
data = json.dumps(data)
else:
data['tok'] = token
if 'access_token' in params:
del params['access_token']
return data
def _proccess_result(self, content):
"""
formate result
"""
try:
return super(AipSpeech, self)._process_result(content)
except Exception as e:
return {
'__json_decode_error': content,
}
# 由于代码量大,以下略...
4、处理baidu_speech_synthesis.py 文件中 disable_warnings()
的导包问题,改写部分方法,修改部分变量命名。
from urllib3 import disable_warnings
from urllib.parse import urlencode
from urllib.parse import quote
from urllib.parse import urlparse
disable_warnings()
5、接口相关参数配置如下图。

接口参数描述.png¶
6、在 AipSpeech 中封装 main 入口方法,我配置 per 为 3 ,选择男生情感合成。
class AipSpeech(AipBase):
"""
Aip Speech
"""
# 中间部分略
def main(self):
"""入口方法"""
api_ = AipSpeech(self._app_id, self._api_key, self._secret_key)
# 我们要合成文本信息保存在 baidu_speech.txt 文件中
with open("baidu_speech.txt", 'r', encoding="utf-8") as read_f:
read_content = read_f.read()
result = api_.synthesis(read_content, 'zh', 1, {'vol': 5, 'per': 3})
# 识别正确返回二进制数据 错误则返回dict码
if not isinstance(result, dict):
# 合成的语音文件名为
with open('baidu_speech.mp3', 'wb') as f:
f.write(result)
以上,便完成了整个百度语音合成的 API 封装,关注公众号,后台回复
语音合成 获取完整源码。
4.使用 API 实现语音合成
1、配置 API 参数,在baidu_speech_synthesis.py最下方定义API调用demo。
if __name__ == '__main__':
app_id = '这里改成你的应用 ID'
api_key = '这里改成你的API 开发密钥'
secret_key = '这里改成你密钥'
AipSpeech(app_id, api_key, secret_key).main()
2、baidu_speech.txt 文件内容如下图(这里使用相见恨晚的歌词测试):

txt文件png.png¶
3、执行完程序,会在同级目录下生成一个名为baidu_speech.mp3的音频文件,下面我可以使用播放工具播放即可。
5.总结
1、原创文章已全部更新至 Github:https://github.com/kelepython/kelepython
2、本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c03/c03_02.html
3、整个实现案例比较简单,建议大家亲自尝试一下。
4、封装代码时一定要细心,建议每次封装完一个小块,就执行验证其正确性。
5、案例合成语音使用中音量、情感合成男声,如果感兴趣,可自行调整参数尝试。
6、关注公众号,后台回复
语音合成获取完整源码,有任何疑问欢迎留言交流。
3.3 实战 | 使用 Python 哄女朋友¶
0. 前言
昨天,和一位朋友聊天,他说最近准备学习 Python 这门编程语言,问我学完
Python 能做哪些事情。
正好,最近他女朋友有点闷闷不乐,他也寻思着给她找点乐子,开心一下。我随口说了句,可以用 Python 哄女朋友呀。
没想到他竟当真了,说完就立马要我实现,今天给大家分享如何使用 Python 哄女朋友。
1. 功能简介
使用 Python 给女朋友发送随机笑话,博得美人一笑。
主要分为两部分功能,一是获取随机笑话,二是将获取的随机笑话发送给女朋友。
使用第三方库 requests 发送 HTTP 请求获取随机笑话,使用第三方库
wxpy 完成微信登录、微信好友列表获取、以及发送微信消息等操作。
以上两个库的安装,可直接使用以下命令:
pip install requests
pip install wxpy
2. 功能实现
2.1 获取随机笑话函数封装
使用 requests 模块发送 HTTP GET
请求,对返回数据进行解析,获取随机笑话内容,并作为函数的返回值返回。
import requests
def get_joke() -> str:
"""获取随机笑话"""
# 1. 随机笑话获取接口 URL
url = "https://autumnfish.cn/api/joke"
# 2. 获取返回数据
joke_data = requests.get(url)
# 3. 解析数据并返回
return joke_data.text
if __name__ == '__main__':
print(get_joke())
调用函数测试,输出结果如下:
老婆趁我午睡,偷偷的到我钱包里拿钱,于是我质问她:“我每月就只有这么点零花钱,你还拿我的,有没有考虑过我的感受?”
老婆:“考虑过啊,所以我到你那拿钱的时候才会轻手轻脚的,怕吵醒你了。”
一时间我竟然有些感动。。。
2.2 网页版微信登录功能实现
wxpy 库中的 bot.py 模块中,封装了一个 Bot 类,我们称之为
机器人对象,主要用于登陆与操作微信,涵盖了大部分网页版微信的功能。
使用以下代码即可完成机器人对象初始化与登录功能:
import wxpy
# 网页版微信登陆
bot = wxpy.Bot()
执行代码后,会弹出二维码信息,使用微信扫码即可登录。
2.3 发送微信消息函数封装
调用机器人对象 bot 的 friends 方法获取微信好友列表, 使用
search
方法搜索指定微信昵称的好友,如你女朋友的微信昵称,并获取数据的第一个对象,调用获取对象的
send 方法发送微信消息。
import wxpy
# 网页版微信登陆
bot = wxpy.Bot()
def send_msg():
"""发送消息给女朋友"""
try:
# 通过微信昵称获取女朋友备注信息
friend = bot.friends().search(u'女朋友的昵称')[0]
# 调用 send 方法发送微信消息
# 发送获取的随机笑话
friend.send(get_joke())
except:
pass
2.4 功能测试
1、执行代码,扫码登录微信。
...
# 以上代码略
if __name__ == '__main__':
send_msg()
2、微信消息发送成功,效果如下图:
3. 功能优化
不难发现,上面的功能存在一些不足,我们每次只能发送一条消息,而且每次发送都得重新运行一下代码,这显然不符合我这位朋友的需求。
现在,我们优化一下代码,保证代码只需要运行一次,还能定时发送消息,并且在随机笑话前面添加自己想要的内容 - "女神,开心一刻:"。
3.1 入口函数封装
我们将所有的业务逻辑全部封装至 main 函数中,便于后续优化、升级,选用
time 模块实现定时功能。
...
# 以上代码略
import time
def main():
"""定时发送消息"""
while True:
send_msg()
# 这里设置间隔时间,单位为秒
time.sleep(10)
if __name__ == '__main__':
main()
这里的时间可根据自身情况设置,这位朋友的需求是一个小时发一次,为了便于测试,我们暂时设置为 10 秒一次。
3.2 发送消息函数调整
调整 send_msg 函数中的业务逻辑,在发送的消息前面加上所需的文本内容。
...
# 以上代码略
def send_msg():
"""发送消息给女朋友"""
try:
# 通过微信昵称获取女朋友备注信息
friend = bot.friends().search(u'女朋友的昵称')[0]
print(get_joke())
# 调用 send 方法发送微信消息
friend.send("女神,开心一刻:\n{}".format(get_joke()))
except:
pass
3.3 优化后的功能效果
执行代码,扫码登录即可成功定时发送消息了,接下来,我们看看效果吧。
4. 补充
打开 bot.py
模块的源码可以发现,里面还封装了很多微信操作相关的方法,有兴趣的朋友可以去了解一下。
下面介绍几个常用的方法:
friends:获取所有微信好友
groups:获取所有微信群聊对象
mps:获取所有公众号
user_details:获取单个或多个用户的详细信息
add_friend:添加指定用户为好友
其实,初始化机器人对象时,也可以传递参数,下面介绍几个常用的参数:
cache_path:当前会话的缓存路径,并开启缓存功能,默认不开启
console_qr:在终端中显示登陆二维码,需要安装
pillow模块,也可为整数,表示二维码单元格的宽度qr_path:保存二维码的路径
5.总结
1、Python 能带给我们很多惊喜,增添生活乐趣,提升学习、工作效率等等。
2、案例中发送的是随机笑话,大家可以根据自身需求,如发送天气预报、新闻、或者其他感兴趣的内容等等。
3、关注公众号,在后台回复 『
哄女朋友』,即可获取完整源码。4、原创文章已全部更新至 Github:https://github.com/kelepython/kelepython。
5、本文永久博客地址:https://kelepython.readthedocs.io/zh/latest/c01/c03_03.html。
6、欢迎在留言区讨论,有任何疑问也可与小编联系,也欢迎大家分享一些有趣使用的知识。